Cannot insert duplicate key. Кто виноват и что делать
#SQL Server
#1С:Предприятие
#оптимизация
#производительность
#базы данных
#ошибки
#уникальность
#индекс
О чем речь
Одним прекрасным днем, приходя на работу, Вы обнаруживаете странные ошибки в системе “Cannot insert duplicate key row in object 'dbo.<имя таблицы>' with unique index '<имя индекса>'". Ошибки могут появляться и на русском языке, если установлена соответствующая локализация: "Не удается вставить повторяющуюся строку в объект "dbo.<имя таблицы>" с уникальным индексом "<имя индекса>".
Появление ошибки может происходить при различных действиях, но единственное что их объединяет - это попытка изменения данных в базе данных (ну? а как иначе, ошибка то на уровне СУБД). Причем характерно это как для файлового режима работы, так и для клиент-серверных баз. В рамках статьи мы будет делать упор на работу через SQL Server, но все актуально и для PostgreSQL.
Чаще всего подобные ошибки появляются при следующих действия:
- Проведение документа, когда он изменяет данные в регистрах.
- Во время обменов данных между базами или другими информационными системами.
- При попытке изменить какой-либо документ в старом периоде, хотя много лет назад он мог проводиться без проблем.
Обычно в таких случаях администраторы или разработчики запускают стандартный инструмент “Тестирование и исправление”, пересчитывают итоги и др. Но давайте разберемся почему так происходит и что стоит делать в тех или иных случаях.
Все, что Вы прочитаете ниже, не является истиной, потому что случаев может быть очень много. Но материал может быть полезен для всех специалистов, обслуживающих базы 1С, т.к. даст понимание что СУБД все же хочет сказать.
Суть проблемы
Вся проблема заключается в том, что платформа пытается добавить в таблицу запись с уже существующими ключевыми полями. Ключевые поля в нашем случае - это те поля, из которых состоит уникальный индекс таблицы. Платформа создает уникальные индексы почти всегда. Вот пример кластерного индекса документа.
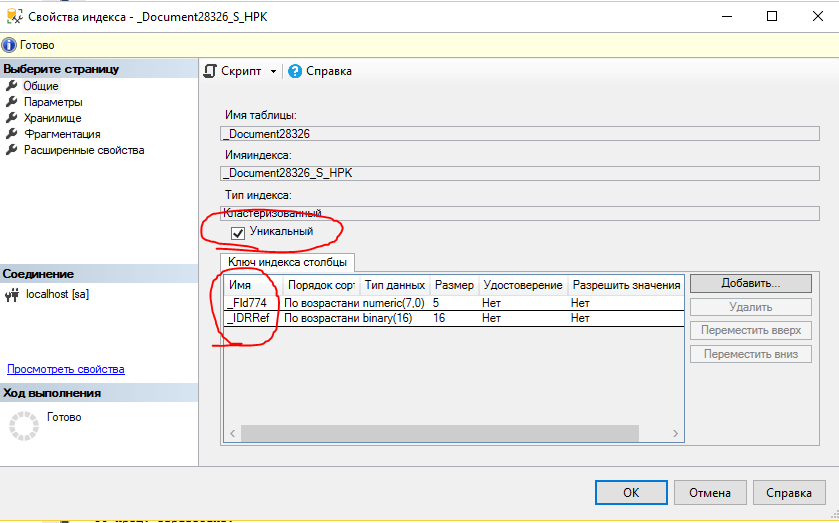
В этом случае индекс состоит из разделителя данных и ссылки, причем комбинация этих полей должны быть уникальными. Уникальность устанавливается и практически для всех остальных индексов. Вот, например, индекс по номеру документа.
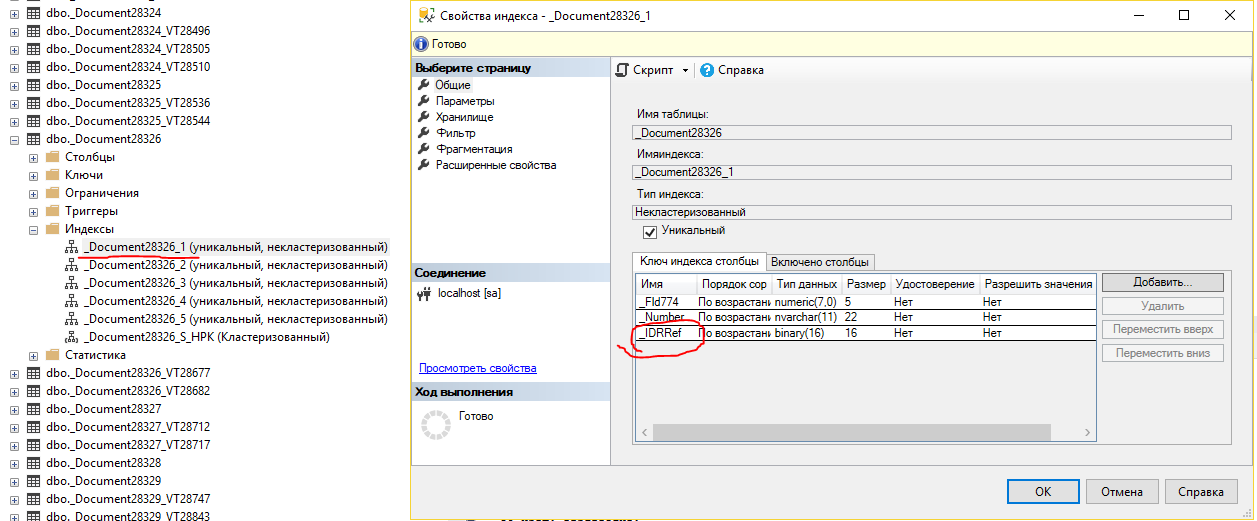
Для того, чтобы соблюдалась уникальность, последним полем добавлена ссылка, ведь номер документа может быть не уникальным (особенно в разных периодах, если нумерация повторяется ежегодно или ежемесячно), а ссылка уникальна практически всегда в рамках одной таблицы.
Никто не может гарантировать, что в рамках одной информационной базы все GUID’ы в таблицах уникальны, т.к. всегда есть вероятность их повторения, особенно если данные из разных баз сливаются в одну. С таким даже сталкивался на практике, когда в двух базах в одной таблицы встретился один GUID у разных элементов!
Но вот уникальность идентификатора в рамках одной таблицы и в одной базе гарантировать можно, хотя бы за счет уникального кластерного индекса.
Если при обмене будет попытка создать элемент с таким же идентификатором в одной таблице, то это приведет к ошибке на уровне СУБД. Пример такого поведения будет ниже.
В этом и заключается проблема - в некоторых ситуациях платформа 1С из-за ошибок в прикладном коде или в самой технологической платформе пытается вставить запись с уникальным идентификатором, который уже есть в базе.
Далее разберем несколько примеров таких случаев и возможные решения.
Не могу создать документ
Иногда встречаются интеграции между системами, которые создают элементы в базе приемнике с такими же GUID’ами, как и в источнике. Это очень удобно, синхронизация по уникальным идентификаторам (ссылкам) самая надежная и простая. Но в этом случае есть бомба замедленного действия - что если в один прекрасный день уникальные идентификаторы для одного и того же объекта метаданных совпадут в разных базах?А если не уникальный?
Конечно, Вы будете говорить что это маловероятно, что нет смысла думать об этом. Ну совпадет и ладно. Просто пересоздадим объект и все, зато код работает хорошо и выглядит просто. Самое плохое тут в том, что ошибка может появится в самый неподходящий момент, например, в закрытие месяца. Окажется что из-за совпадения идентификатора не создался документ партии и все полетело к %I$#@(^. Интеграция ошибку не показала, а просто ее пропустила, никто не заметил и месяц уже закрыли. Все.
В типовых конфигурациях синхронизация объектов тоже выполняется по уникальным идентификаторам (ссылка), но через промежуточный объект - регистр сведений “СоответствияОбъектовИнформационныхБаз”, который решает описанную выше проблему. Регистр хранит соответствие объектов в разных системах и уже становится не важно, что идентификаторы между ними могут совпасть. Обмен все это решит, а соответствие запишется в эту таблицу. Хотя и тут бывают сложности, но это уже другая история.
Вы можете воспроизвести подобную ошибку вставки просто выполнив подобный код.
GUID = Новый УникальныйИдентификатор();НовЭлемент = Документы.ТестовыйДокумент.СоздатьДокумент();СсылкаНовогоЭлемента = Документы.ТестовыйДокумент.ПолучитьСсылку(GUID);НовЭлемент.УстановитьСсылкуНового(СсылкаНовогоЭлемента);НовЭлемент.Дата = ТекущаяДата();НовЭлемент.Записать();НовЭлемент = Документы.ТестовыйДокумент.СоздатьДокумент();СсылкаНовогоЭлемента = Документы.ТестовыйДокумент.ПолучитьСсылку(GUID);НовЭлемент.УстановитьСсылкуНового(СсылкаНовогоЭлемента);НовЭлемент.Дата = ТекущаяДата();// При попытке записи объекта с тем же идентификатором// получим ошибкуНовЭлемент.Записать();
Ошибка, например, может быть такой. Все зависит от названия таблиц для метаданных.
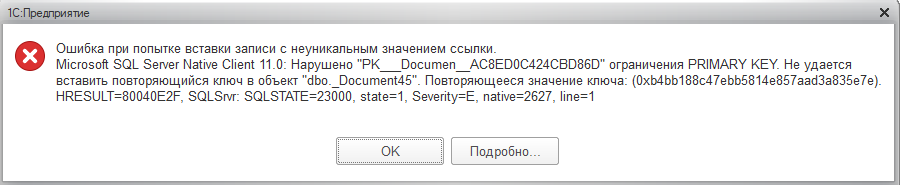
В этом случае решением будет - делать соответствие объектов между обмениваемыми системами и не идти по правилу “один GUID для элемента во всех базах”.
Это был самый простой случай, но он уже должен был Вас привести к мысли, что синхронизация по идентификаторам в обменах иногда может быть опасной. Вы можете не верить в это до последнего момента, но потом может быть уже поздно!
Проблема при записи регистров
Эта проблема наиболее интересная и сложная, да и встречается она чаще. Регистры, как Вы уже поняли, тоже имеют уникальные индексы по ключевым полям. Для регистров уникальность проверяется в разрезе их измерений.
Простой пример
Есть независимый непериодический регистр сведений “ДанныеДоговоровКонтрагентов” с такой структурой.
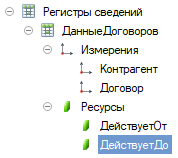
Если попытаться записать в него данные с повторяющимися значениями контрагента и договора, то мы поймаем такую ошибку.
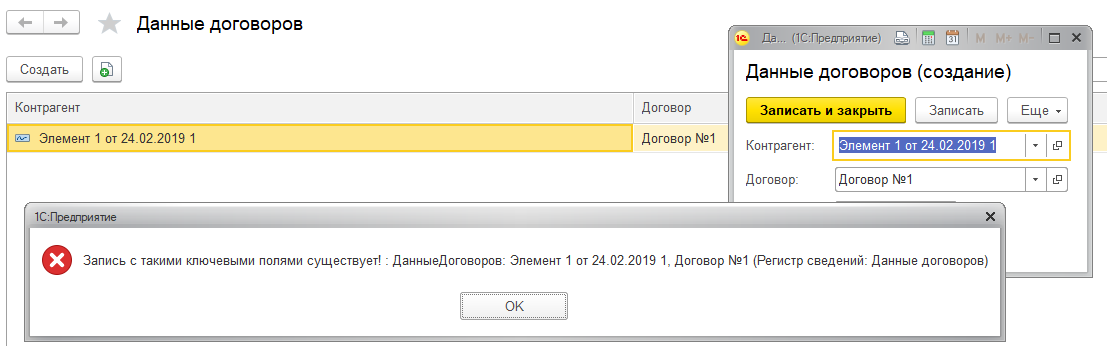
То есть платформа контролирует уникальность самостоятельно, в отличии от записи объектов (документов, справочников и т.д.) с одинаковой ссылкой. Это можно определить просто взглянув на сообщение об ошибке, там нет никаких признаков, что исключение появилось на уровне СУБД. Но рано радоваться, возьмем сложный пример - регистр бухгалтерии.
Что же с данными моими стало
Думаю, с этим многие могли сталкиваться - при попытке провести документ прошлого периода возникает ошибка на таблицах регистра бухгалтерии примерно такого вида.
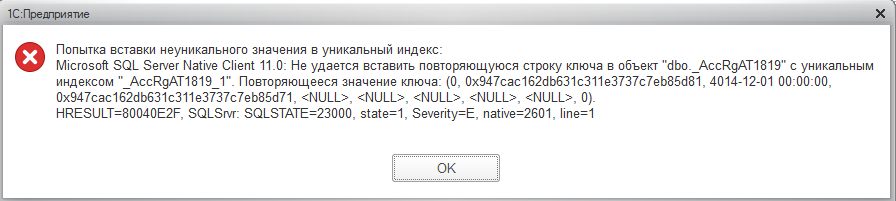
История возникновения у каждого своя, но типичные случаи все же:
- Нужно изменить записи бухгалтерского регистра в прошлом периоде
- Нужно дозагрузить данные в текущий или прошлый период
- Нет никакой предыстории, просто при вводе новой операции вот такая ошибка :).
Прежде чем говорить о решении отметим, что регистр состоит из следующих таблиц.
| Метаданные | Назначение | Имя таблицы SQL |
|---|---|---|
| РегистрБухгалтерии.Хозрасчетный | Основная | _AccRg786 |
| РегистрБухгалтерии.Хозрасчетный | ИтогиПоСчетам | _AccRgAT0800 |
| РегистрБухгалтерии.Хозрасчетный | ИтогиПоСчетамССубконто1 | _AccRgAT1819 |
| РегистрБухгалтерии.Хозрасчетный | ИтогиПоСчетамССубконто2 | _AccRgAT2820 |
| РегистрБухгалтерии.Хозрасчетный | ИтогиПоСчетамССубконто3 | _AccRgAT3821 |
| РегистрБухгалтерии.Хозрасчетный | ИтогиМеждуСчетами | _AccRgCT822 |
| РегистрБухгалтерии.Хозрасчетный | ЗначенияСубконто | _AccRgED823 |
| РегистрБухгалтерии.Хозрасчетный | НастройкиХраненияИтоговРегистраБухгалтерии | _AccRgOpt825 |
Ошибка вставки не уникального значения была на таблице “_AccRgAT1819”, а эта таблица итогов по счетам с субконто 1. Пока это ничего не дает, рассмотрим варианты решения.
Если проблема у Вас горит и хочется попробовать сразу исправить ее рецептами ниже, то сразу говорю: “Ответственность за все действия лежит только на Вас! Делайте бэкап базы! А если не уверены в своих силах, то пригласите компетентного специалиста.
Вариант №1: Просто отключи итоги
Поистине, самый простой вариант, даже инструкцию можно не писать. Шаги простые:
- Полностью отключаем итоги по регистру.
- Перепроводим / создаем / удаляем нужный документ.
- Включаем итоги обратно.
Вот и все!
Для ускорения пересчета итогов можно очистить таблицы (не для файловых баз) с помощью операции “TRUNCATE TABLE <ИмяТаблицы>, тогда платформа не будет долго удалять старые записи итогов, а сразу перейдет к расчету новых. Не забудьте перед этим сделать бэкап! В нашем случае, удаление предыдущих итогов будет таким:
-- ИтогиПоСчетамTRUNCATE TABLE _AccRgAT0800;-- ИтогиПоСчетамССубконто1TRUNCATE TABLE _AccRgAT1819;-- ИтогиПоСчетамССубконто2TRUNCATE TABLE _AccRgAT2820;-- ИтогиПоСчетамССубконто3TRUNCATE TABLE _AccRgAT3821;-- ИтогиМеждуСчетамиTRUNCATE TABLE _AccRgCT822;
Но такой вариант подходит не всем. Вот его основные минусы, которые могут быть очень критичными для проводимых работ:
- На больших базах пересчет итогов может занимать сутки, двое и даже больше. Иногда это не “лезет” ни в какие технологические окна для обслуживания и пересчет выполнить просто невозможно.
- Пересчет итогов может исправить некоторые старые, устоявшиеся ошибки. Все знают правило - если ошибка в данных не исправляется длительное время, то она превращается в особенность :). То есть пересчет может привести к повреждению старой отчетности и непредвиденным последствиям в поведении различных алгоритмов.
Применять его или нет - решать Вам, но если есть риск нестабильной работы системы после этого, то я бы не стал. Если же за “качеством” итогов Вы следите и пересчет для Вас обычное дело, то почему бы и нет? Дальше уже рассмотрим хардкорные варианты.
Вариант №2: Удаление дублей записей
Можно попытаться найти дубли записей и что-то с ними сделать. В нашем случае для поиска дублей записей в таблице “_AccRgAT1819” можно воспользоваться таким скриптом:
SELECTCOUNT(*) [RowCount],-- Список измерений, которые содержатся в основном кластером индексе[_Fld774],[_AccountRRef],[_Period],[_Fld787RRef],[_Value1_TYPE],[_Value1_RTRef],[_Value1_RRRef],[_Fld788RRef],[_Fld789RRef],-- Разделитель записей в режиме разделения итогов[_Splitter]FROM [dbo].[_AccRgAT1819]GROUP BY-- Список измерений, которые содержатся в основном кластером индексе[_Fld774],[_AccountRRef],[_Period],[_Fld787RRef],[_Value1_TYPE],[_Value1_RTRef],[_Value1_RRRef],[_Fld788RRef],[_Fld789RRef],-- Разделитель записей в режиме разделения итогов[_Splitter]HAVING COUNT(*) > 1
В каждом случае скрипт выглядит по своему, но общий шаблон такой.
SELECTCOUNT(*) [RowCount],-- Список измерений, которые содержатся в основном кластером индексе'Список измерений. Можно посмотреть в основном кластерном индексе' AS [Измерения]FROM [dbo].[_AccRgAT1819]GROUP BY-- Список измерений, которые содержатся в основном кластером индексе'Список измерений. Можно посмотреть в основном кластерном индексе'HAVING COUNT(*) > 1
После того как дубли записей будут найдены можно выполнить одно из следующих действий над ними:
- Удалить из базы, если они действительно не нужны. Стоит учесть, что нужно будет удалить не только из одной таблицы, но и из всех связанных таблиц регистра (таблиц итогов несколько, нужно это понимать).
- Исправить данные как нужно с учетом также нескольких таблиц итогов.
- “Схлопнуть” данные по измерениям (полям кластерного индекса), тем самым убрав дубли.
Готовых скриптов тут не будет, т.к. каждый случай требует своего подхода. Самое главное, чтобы все действия выполнял человек, компетентный в SQL-синтаксисе запросов. Сразу скажу, что в нашем примере дублей строк не было, то есть этот способ нам не подходит. Опыт показывает, что обычно дубли строк в таблице отсутствуют.
Зато этим подходом можно найти случаи, когда дублей по полям индекса нет, но есть много дублей без учета поля-разделителя “_Splitter”, который используется при включенном разделении итогов. Платформа 1С иногда может вставить в таблицу итогов повторяющуюся запись с таким же значением разделителя. Ниже расскажу о возможных причинах такого поведения и как это обходить.
Вариант №3: Отключаем уникальность индекса
Это 100% рабочий вариант, но только в качестве временного решения. Просто берем о перестраиваем индекс с отключением уникальности.
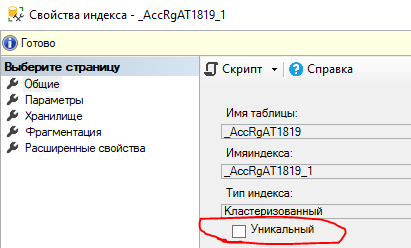
После этого никаких проблем не будет при записи проблемного документа. Почему это временное решение?
- При реструктуризации платформа восстановит уникальность индекса, что приведет к той же ошибке, которую мы пытались обойти.
- Индекс будет работать менее эффективно после отключения уникальности.
- Если не разобраться почему появляются дубли записей в итогах, то можно столкнуться с еще более интересными последствиями в будущем.
Но как временное решение способ идеальный. Можно отключить уникальность, а потом с помощью способов 1 или 2 исправить итоги. Или поискать причину дублей, просто проанализировав записи в итогах.
Вариант №4: Ручная корректировка данных
Самый хардкорный способ, доступный только постигшим дзен платформы 1С и принципы ее работы. Заключается в следующем - пишем SQL-запросы для ручной корректировки данных как в таблице движений и таблице субконто, так и в таблицах итогов.
Это крайний вариант, когда другие способы не помогают. На практике было только один раз, и то его пришлось использовать из-за очень большого объема данных.
Примеров к нему нет смысла давать. Кому нужно, тот сам поймет и выстрадает :).
А что все таки было
В нашем случае могли бы помочь 1, 2 и 4 способ, но что же все таки было? Почему создавались дубли записей? И почему дублей не было до попытки записать проблемный документ?
Ситуация для меня была очень интересной. Итоги пересчитывать было нельзя, дублей записей в таблице тоже не было. Отключил уникальность индекса и провел документ. Вот что появилось в таблице итогов (показана часть таблицы).
| Счет | Период | Вид субконто | Тип субконто | Значение субконто | Остаток | Оборот Дт | Оборот Кт | Оборот |
|---|---|---|---|---|---|---|---|---|
| <ссылка> | 01.12.4014 0:00 | NULL | NULL | NULL | 0.00 | 1000 | 0.00 | 1000 |
| <ссылка> | 01.12.4014 0:00 | NULL | NULL | NULL | 0.00 | -1000 | 0.00 | -1000 |
| <ссылка> | 01.01.4015 0:00 | NULL | NULL | NULL | 1000 | 0 | 0 | 0 |
| <ссылка> | 01.01.4015 0:00 | NULL | NULL | NULL | -1000 | 0 | 0 | 0 |
| <ссылка> | 01.02.4015 0:00 | NULL | NULL | NULL | 1000 | 0 | 0 | 0 |
| <ссылка> | 01.02.4015 0:00 | NULL | NULL | NULL | -1000 | 0 | 0 | 0 |
| <ссылка> | 01.03.4015 0:00 | NULL | NULL | NULL | 1000 | 0 | 0 | 0 |
| <ссылка> | 01.03.4015 0:00 | NULL | NULL | NULL | -1000 | 0 | 0 | 0 |
| <ссылка> | 01.04.4015 0:00 | NULL | NULL | NULL | 1000 | 0 | 0 | 0 |
| <ссылка> | 01.04.4015 0:00 | NULL | NULL | NULL | -1000 | 0 | 0 | 0 |
| <ссылка> | 01.05.4015 0:00 | NULL | NULL | NULL | 1000 | 0 | 0 | 0 |
| <ссылка> | 01.05.4015 0:00 | NULL | NULL | NULL | -1000 | 0 | 0 | 0 |
| <ссылка> | 01.06.4015 0:00 | NULL | NULL | NULL | 1000 | 0 | 0 | 0 |
| <ссылка> | 01.06.4015 0:00 | NULL | NULL | NULL | -1000 | 0 | 0 | 0 |
При редактировании документа из него удалялась запись из табличной части, что приводило к удалению соответствующей записи и в регистре бухгалтерии. Документ из прошлого периода, 2014 года, поэтому при изменении платформа не удаляет записи из таблицы итого, а сторнирует их!
Но вот ошибка - запись сторно выполняется полностью с той же аналитикой, что и основная запись, что и приводит к исключению неуникальной записи в индексе. Одинаковое даже значение разделителя данных. Поэтому мы и не видели до этого дубли записей в таблице, их просто еще не было.
Но почему в одних случаях изменение данных прошлых периодов проходит без ошибки, а в других мы наступаем на грабли и разбиваем себе лицо? И тут тоже все просто! Виновата некорректная аналитика по субконто. У счета в проводке должна стоять аналитика по 1 субконто. В таблице выше заметно, что тип, вид и значение субконто - все NULL! При подготовке данных для записи в таблицы регистра, платформа выполняет различные запросы, в которых можно заметить такие соединения как:
-- Примеры соединения двух таблиц, где-- Т1 - временная таблица с подготовленными данными-- Т2 - таблица итогов "_AccRgAT1819"T1._Value1_TYPE = T2._Value1_TYPE AND T1._Value1_RTRef = T2._Value1_RTRef
Но т.к. значение у этих полей NULL, то запрос возвращает не те данные, что ожидается, т.к. сравниваются значения NULL. SQL Server использует трехзначную логику, при сравнении значения с NULL всегда будет NULL. В этом случае один из запросов не обновляет текущие записи в таблице итогов как положено, т.к. просто не видит их. Пример запроса, в котором выполняется обновление существующих записей итогов, Вы можете увидеть под спойлером. Там же комментариями выделено проблемное место, из-за которого этот запрос не отрабатывает как нужно - не обновляет существующую запись итогов.
UPDATE T2 SET_Fld790 = T2._Fld790 + T1._Fld790,_TurnoverDt801 = T2._TurnoverDt801 + T1._TurnoverDt801,_TurnoverCt802 = T2._TurnoverCt802 + T1._TurnoverCt802,_Turnover803 = T2._Turnover803 + T1._Turnover803,_Fld791 = T2._Fld791 + T1._Fld791,_TurnoverDt804 = T2._TurnoverDt804 + T1._TurnoverDt804,_TurnoverCt805 = T2._TurnoverCt805 + T1._TurnoverCt805,_Turnover806 = T2._Turnover806 + T1._Turnover806,_Fld792 = T2._Fld792 + T1._Fld792,_TurnoverDt807 = T2._TurnoverDt807 + T1._TurnoverDt807,_TurnoverCt808 = T2._TurnoverCt808 + T1._TurnoverCt808,_Turnover809 = T2._Turnover809 + T1._Turnover809,_Fld793 = T2._Fld793 + T1._Fld793,_TurnoverDt810 = T2._TurnoverDt810 + T1._TurnoverDt810,_TurnoverCt811 = T2._TurnoverCt811 + T1._TurnoverCt811,_Turnover812 = T2._Turnover812 + T1._Turnover812,_Fld794 = T2._Fld794 + T1._Fld794,_TurnoverDt813 = T2._TurnoverDt813 + T1._TurnoverDt813,_TurnoverCt814 = T2._TurnoverCt814 + T1._TurnoverCt814,_Turnover815 = T2._Turnover815 + T1._Turnover815,_Fld795 = T2._Fld795 + T1._Fld795,_TurnoverDt816 = T2._TurnoverDt816 + T1._TurnoverDt816,_TurnoverCt817 = T2._TurnoverCt817 + T1._TurnoverCt817,_Turnover818 = T2._Turnover818 + T1._Turnover818FROM #tt57 T1 WITH(NOLOCK)INNER JOIN dbo._AccRgAT1819 T2ON T1._Period = T2._PeriodAND T1._AccountRRef = T2._AccountRRefAND T1._Fld787RRef = T2._Fld787RRefAND ((T1._Fld788RRef = T2._Fld788RRef OR T1._Fld788RRef IS NULL AND T2._Fld788RRef IS NULL))AND ((T1._Fld789RRef = T2._Fld789RRef OR T1._Fld789RRef IS NULL AND T2._Fld789RRef IS NULL))AND T1._Fld774 = T2._Fld774-- Вот тут и проблема. Т.к. в таблице итогов эти поля имеют значения NULL,-- то обновление этих записей просто не выполняется как нужноAND T1._Value1_TYPE = T2._Value1_TYPEAND T1._Value1_RTRef = T2._Value1_RTRefAND T1._Value1_RRRef = T2._Value1_RRRefAND T2._Splitter = @P1WHERE (T1._EDCount = @P2) AND (T2._Fld774 = @P3)
В случае, если платформа не находит записи итогов для обновления, как это случилось в прошлом запросе, то выполняется попытка добавления недостающих записей итогов. Под спойлером запрос с комментариями в важных частях.
INSERT INTO dbo._AccRgAT1819(_Period,_AccountRRef,_Fld787RRef,_Fld788RRef,_Fld789RRef,_Fld774,_Value1_TYPE,_Value1_RTRef,_Value1_RRRef,_Fld790,_TurnoverDt801,_TurnoverCt802,_Turnover803,_Fld791,_TurnoverDt804,_TurnoverCt805,_Turnover806,_Fld792,_TurnoverDt807,_TurnoverCt808,_Turnover809,_Fld793,_TurnoverDt810,_TurnoverCt811,_Turnover812,_Fld794,_TurnoverDt813,_TurnoverCt814,_Turnover815,_Fld795,_TurnoverDt816,_TurnoverCt817,_Turnover818,_Splitter)SELECTT1._Period,T1._AccountRRef,T1._Fld787RRef,T1._Fld788RRef,T1._Fld789RRef,CAST(CASE WHEN (1=1) AND CASE WHEN 1=1 THEN CASE WHEN (T1._Fld774) = 0.0 OR (T1._Fld774) = 0.0 THEN 0 ELSE 2000000000 END + 2000000000 ELSE 0 END = 2000000000 THEN 0.0 END AS NUMERIC(7, 0)),T1._Value1_TYPE,T1._Value1_RTRef,T1._Value1_RRRef,T1._Fld790,T1._TurnoverDt801,T1._TurnoverCt802,T1._Turnover803,T1._Fld791,T1._TurnoverDt804,T1._TurnoverCt805,T1._Turnover806,T1._Fld792,T1._TurnoverDt807,T1._TurnoverCt808,T1._Turnover809,T1._Fld793,T1._TurnoverDt810,T1._TurnoverCt811,T1._Turnover812,T1._Fld794,T1._TurnoverDt813,T1._TurnoverCt814,T1._Turnover815,T1._Fld795,T1._TurnoverDt816,T1._TurnoverCt817,T1._Turnover818,CAST(0.0 AS NUMERIC(10, 0))-- К временной таблице "#tt57" присоединяется таблица итогов по 1 субконто "_AccRgAT1819"FROM #tt57 T1 WITH(NOLOCK)LEFT OUTER JOIN dbo._AccRgAT1819 T2ON (T1._Period = T2._PeriodAND T1._AccountRRef = T2._AccountRRefAND T1._Fld787RRef = T2._Fld787RRefAND ((T1._Fld788RRef = T2._Fld788RRef OR T1._Fld788RRef IS NULL AND T2._Fld788RRef IS NULL))AND ((T1._Fld789RRef = T2._Fld789RRef OR T1._Fld789RRef IS NULL AND T2._Fld789RRef IS NULL))AND T1._Fld774 = T2._Fld774-- Здесь проблемное соединение из-за значений NULL в полях субконто таблицы итоговAND T1._Value1_TYPE = T2._Value1_TYPEAND T1._Value1_RTRef = T2._Value1_RTRefAND T1._Value1_RRRef = T2._Value1_RRRefAND T2._Splitter = @P1)AND (T2._Fld774 = @P2)-- Добавлена проверка, что вставка новой записи в таблицу итогов будет выполнена-- только если нет существующей записи в этой таблице.-- Из-за значений NULL "старая" запись не находится, поэтому и появляется эта операция-- вставки данныхWHERE T2._Period IS NULLAND T1._EDCount = @P3
Но, поскольку запись итогов все же уже есть в таблице, то происходит ошибка “Cannot insert duplicate key”.
Проверить работу СУБД с NULL можно вот таким запросом. Попробуйте и поймете что тут к чему. Подробнее об обработке значений NULL можно прочитать тут.
ВЫБРАТЬNULL ЕСТЬ NULL КАК Поле1,NULL = NULL КАК Поле2,NULL = ЛОЖЬ КАК Поле3,NULL <> NULL КАК Поле4,NULL ЕСТЬ НЕ NULL КАК Поле5
Вот такие дела. Мы рассмотрели не самый простой пример с ошибкой дублирования записи в таблице. Бывают ошибки проще Теперь ты знаешьна других таблицах и объектах метаданных. Хотя и бывают ситуации еще сложнее, когда ошибка воспроизводится спонтанно, на разных документах. Основные причины ошибки те же самые, просто “интересных” данных в регистре уже намного больше.
Не загружается DT’шник базы
Иногда подобная ошибка встречается при переводе базы из файлового варианта в клиент-серверный через загрузку-выгрузку DT-файла.
На практике относительно мало работал с файловыми базами, но решать проблему удавалось двумя способами:
- Удалением или редактированием битых записей перед выгрузкой в DT. Это можно сделать через режим 1С:Предприятие, если проблема в основных таблицах. Или можно воспользоваться утилитой Tool1CD.
- В момент загрузки DT на SQL Server сделать триггер при создании и отключить ему уникальность с помощью скрипта. Далее уже анализировать проблему.
Иногда может помочь штатное тестирование и исправление, но этот инструмент не является панацеей от всех болезней. А иногда он может и навредить, используйте с умом!
Способы не универсальные, нужно смотреть по ситуации.
Что имеем в итоге
Какой сделать вывод? Проблемы вставки не уникальной записи - это не баг СУБД! Основные причины таких ошибок:
- Некорректные данные в таблицах, появившееся либо в результате некорректной работы программного кода, либо из-за ошибок платформы 1С, либо при изменении учета “на лету”, когда, например, изменяют состав субконто.
- Ошибки в коде прикладных решений.
- Плохое обслуживание итогов в регистрах, отсутствие проактивной сверки данных, при которой такие проблемы решались бы оперативней.
К счастью, все подобные вопросы можно решить и в абсолютном большинстве случаев без жертв.
Платформа 1С может быть более внимательной к данным, а разработчики прикладных решений дальновидней в плане архитектуры и инструментов сопровождения.
Конечно, описать все подобные ситуации нельзя в рамках только одной публикации.