Секционирование таблиц и индексов в мире 1С
#SQL Server
#1С:Предприятие
#оптимизация
#производительность
#базы данных
#секционирование
Зачем все это
Файловые группы! Секционирование таблиц и индексов! Размещение таблицы на нескольких дисках! Собственные индексы для таблиц и другие замечательные возможности СУБД, которые платформа 1С не поддерживает “из коробки”.
Все это применяется во многих других системах, но не у нас, ведь мы используем более продвинутые технологии:
- Нет смысла разделять базу, таблицы или индексы на отдельные файлы для распределения по дискам, ведь в век SSD это пустая трата времени.
- База стала большой, неповоротливой и с множеством ошибок в данных? Начнем жизнь с чистого листа (ну или почти с чистого) - свертка базы все решает!
- Ускорение бэкапирования за счет отказа от сохранения исторических данных в базе - тоже не про нас. Ведь бэкапировать один файл базы удобнее.
- Проблемы блокировок и неактуальных статистик вообще к нам не относятся, потому что платформа 1С сама все оптимизирует.
Уже сейчас на просторах нашей Родины все чаще можно встретить внедрения информационных систем на базе 1С с активным количество пользователей более 1000, а размером баз более 1 ТБ. Я думаю (или очень сильно надеюсь), что именно при подобных внедрениях работа с базами 1С меняется, а это привносит новые требования как к самой платформе, так и к необходимым компетенциям администраторов и разработчиков. Одним из таких требований является иной подход к обслуживанию базы данных, который нельзя сделать стандартными средствами платформы 1С. Как вы могли догадаться, речь идет о секционировании таблиц и индексов.
Одним из самых важных требований к обслуживанию больших, высоконагруженных баз является эффективная структура индексов, которую нельзя полностью создать средствами платформы 1С. Но об этом мы уже говорили в предыдущей статье “Создаем свои индексы для баз 1С. Со своей структурой и настройками!”, поэтому сейчас на этом заострять внимание не будем.
Ниже поговорим об использовании секционирования таблиц и индексов в базах 1С, плюсах и минусах, подводных камнях и целесообразности.
Все, что будет ниже, относится к клиент-серверному режиму работы и рассматривается в контексте Microsoft SQL Server. Но, фактически, может быть использовано и на PostgreSQL.
В статье нет раскрытия вопроса лицензирования SQL Server и доступности функций в зависимости от редакции СУБД. Подробности Вы можете узнать здесь.
Принцип работы
Что же такое секционирование и для чего оно используется? В общих чертах, секционирование - это разбиение таблиц и индексов на некоторые блоки, в качестве которых может выступать файловая группа (логическое разделение) или файл (физическое разбиение). Блоки могут быть разных размеров, находиться на разных дисках и иметь различные специфичные для них настройки. Как обычно, вся самая подробная информация о секционировании SQL Server находится в официальной документации, мы же рассмотрим несколько примеров его использования с описанием плюсов и минусов этого подхода.
Для SQL Server создание секций выполняется в несколько этапов. Опустим этап проектирования и рассмотрим по шагам простой пример. У нас есть информационная база 1С “Partitioning”, структура метаданных которой состоит из 2 документов, 4 регистров накопления и 4 справочников.
Структура метаданных дана просто для информации, все примеры будут на 1 или 2 таблицах. Как можно догадаться, примеры с секционированием будут выполнены на регистрах “Продажи_Секции” и “ТоварыНаСкладах_Секции”. На стороне SQL Server эти объекты представлены несколькими таблицами. Нас интересуют только физические таблицы для упрощения примеров. Таблицы итогов и служебные таблицы секционировать не будем.
| Метаданные | Имя таблицы | Поле 1С | Поле SQL |
|---|---|---|---|
| РегистрНакопления.ТоварыНаСкладах_Секции | _AccumRg84 | Период | _Period |
| ⬆️ | ⬆️ | Регистратор | _RecorderTRef |
| ⬆️ | ⬆️ | Регистратор | _RecorderRRef |
| ⬆️ | ⬆️ | НомерСтроки | _LineNo |
| ⬆️ | ⬆️ | Активность | _Active |
| ⬆️ | ⬆️ | ВидДвижения | _RecordKind |
| ⬆️ | ⬆️ | Склад | _Fld85RRef |
| ⬆️ | ⬆️ | Номенклатура | _Fld86RRef |
| ⬆️ | ⬆️ | Количество | _Fld87 |
| РегистрНакопления.Продажи_Секции | _AccumRg69 | Период | _Period |
| ⬆️ | ⬆️ | Регистратор | _RecorderRRef |
| ⬆️ | ⬆️ | НомерСтроки | _LineNo |
| ⬆️ | ⬆️ | Активность | _Active |
| ⬆️ | ⬆️ | Подразделение | _Fld70RRef |
| ⬆️ | ⬆️ | Контрагент | _Fld71RRef |
| ⬆️ | ⬆️ | Сумма | _Fld72 |
Все таблицы базы содержат данные с 2010 до 2019 года, чтобы наглядно продемонстрировать действия секционирования.
Создание файловых групп
Для начала создадим логические блоки базы данных - файловые группы. Сделать это можно как с помощью SQL-скрипта, так и с помощью графического интерфейса в SQL Managment Studio (SSMS).
USE [master]GOALTER DATABASE [Partitioning] ADD FILEGROUP [FG1]GOALTER DATABASE [Partitioning] ADD FILEGROUP [FG2]GOALTER DATABASE [Partitioning] ADD FILEGROUP [FG3]GO
В результате, кроме основной файловой группы PRIMARY имеем три дополнительных: FG1, FG2, FG3.
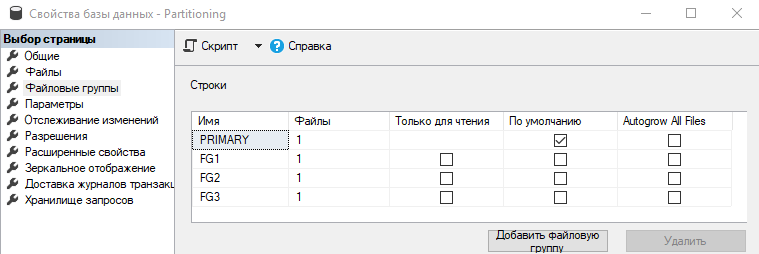
Файловые группы необходимы для распределения данных по ним с помощью секционирования. За файловой группой может стоять как отдельный файл или группа файлов.
Добавление файлов
Файловые группы есть, но они нигде не используются. Добавим отдельные файлы для каждой файловой группы.
USE [master]GOALTER DATABASE [Partitioning] ADD FILE (-- Настройки размещения и автоувеличение файлаNAME = N'Partitioning_FG1',FILENAME = N'D:\DBs\Partitioning_FG1.ndf' ,SIZE = 1024KB ,FILEGROWTH = 10%)-- Принадлежность файла к файловой группеTO FILEGROUP [FG1]GOALTER DATABASE [Partitioning] ADD FILE (NAME = N'Partitioning_FG2',FILENAME = N'D:\DBs\Partitioning_FG2.ndf', SIZE = 1024KB, FILEGROWTH = 10%)TO FILEGROUP [FG2]GOALTER DATABASE [Partitioning] ADD FILE (NAME = N'Partitioning_FG3',FILENAME = N'D:\DBs\Partitioning_FG3.ndf', SIZE = 1024KB, FILEGROWTH = 10%)TO FILEGROUP [FG3]GO
Теперь каждая файловая группа ассоциирована с отдельным физическим файлом. Эти файлы также сразу же доступны в файловой системе.
Определение функции и схемы секционирования
Тут начинается самое интересное. Нам необходимо определить как данные в таблице или индексах будут распределяться между секциями. Для этого используются функции секционирования. Как упоминалось выше, таблицы содержат данные с 2010 по 2019 год. Допустим, нам нужно распределить данные по годам между секциями по такому принципу:
| Файловая группа | Фильтр данных |
|---|---|
| FG1 | до 2010 года включительно |
| FG2 | с 2011 по 2014 год включительно |
| FG3 | с 2015 по 2018 год включительно |
| PRIMARY | с 2019 года по текущий момент |
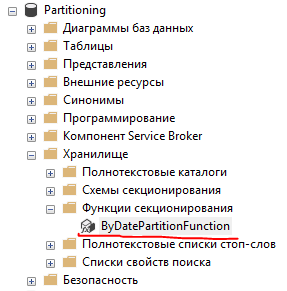
Создать функцию секционирования можно только с помощью SQL-скрипта. В нашем случае он будет выглядеть так.
USE [Partitioning]GOCREATE PARTITION FUNCTION [ByDatePartitionFunction]-- Тип колонки исходной таблицы, по которой-- будет выполняться секционирование(datetime2(0))-- Указание к какой области интервала значений-- принадлежит аргумент в части "FOR VALUES"AS RANGE LEFT-- Платформа 1С хранит даты с некоторым смещением,-- которое обычно установлено в 2000 лет, чтобы-- иметь возможность хранить пустую дату "01.01.0001"-- из 1С в виде "01.01.2001" на стороне SQL Server.-- Поэтому здесь все даты в 4-ом тысячелетии :)FOR VALUES (N'4010-12-31T23:59:59.000',N'4014-12-31T23:59:59.000',N'4018-12-31T23:59:59.000')GO
Тип колонки секционирования соответствует типы поля “_Period” в таблице регистра. Через SSMS можно увидеть новый объект в разделе “Хранилище”.
Но функции еще недостаточно, чтобы применить секционирование на практике. Нам еще нужна схема секционирования, которая с помощью функции свяжет секции таблицы или индекса с файловыми группами. Выше в таблице было описание как такое сопоставление должно быть сделано, нам осталось лишь написать скрипт.
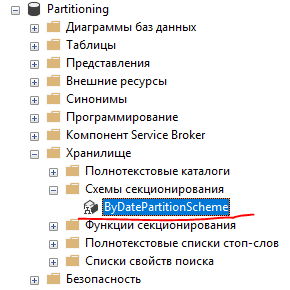
USE [Partitioning]GOCREATE PARTITION SCHEME [ByDatePartitionScheme]-- Используемая функция секционированияAS PARTITION [ByDatePartitionFunction]-- Файловые группы указаны в том порядке,-- в котором указаны значения фильтров-- при создании функции секционированияTO ([FG1], [FG2], [FG3], [PRIMARY])GO
В списке объектов базы созданную схему можно также заменить в разделе “Хранилище”.
И так, функция и схема секционирования готовы, осталось применить их на таблицах / индексах.
Применяем секционирование
Выше уже было сказано, что пример секционирования будет выполняться на таблицах двух регистров накопления:
- “ТоварыНаСкладах_Секции” (таблица “_AccumRg84”)
- “Продажи_Секции” (таблица “_AccumRg69”)
Обе таблицы имеют кластерный индекс, поэтому будет достаточно применить схему секционирования к нему и всем некластеризованным индексам (которых у каждой таблицы по 1 для полей “Регистратор” + “НомерСтроки”). Для этого необходимо пересоздать индексы с явным указанием схемы секционирования. Вот полный скрипт для таблицы “_AccumRg84”. Для “_AccumRg69” скрипт будет аналогичным, только имя таблицы и индексов нужно поменять.
USE [Partitioning]GOCREATE UNIQUE CLUSTERED INDEX [_AccumRg84_1] ON [dbo].[_AccumRg84]([_Period] ASC,[_RecorderTRef] ASC,[_RecorderRRef] ASC,[_LineNo] ASC)WITH (-- Пересоздать индекс заново, если существуетDROP_EXISTING = ON,-- Включить инкрементальную статистику-- Об этом в статье далееSTATISTICS_INCREMENTAL = ON)-- Указываем схему секционирования и колонку таблицы,-- к которой эта схема применяетсяON [ByDatePartitionScheme](_Period)GOCREATE UNIQUE NONCLUSTERED INDEX [_AccumRg84_2] ON [dbo].[_AccumRg84]([_RecorderTRef] ASC,[_RecorderRRef] ASC,[_LineNo] ASC-- Для секционирования в индексе должен присутствовать столбец секционирования-- поэтому стандартный платформенный индекс приходится изменять[_Period] ASC)WITH (DROP_EXISTING = ON,STATISTICS_INCREMENTAL = ON)ON [ByDatePartitionScheme](_Period)GO
Для упрощения составления скрипта можно использовать возможности SSMS по генерации DDL-команд для существующих объектов (таблицы и индексы). Сформированные автоматически скрипты можно использовать как шаблоны. Результатом скрипта будет разбиение таблиц и ее индексов на секции. Проверим результат для таблицы “_AccumRg84” и ее кластерного индекса с помощью этого скрипта.
| Номер секции | Количество строк в секции |
|---|---|
| 1 (FG1) | 4111890 |
| 2 (FG2) | 1059512 |
| 3 (FG3) | 82034 |
| 4 (PRIMARY) | 536 |
Итог: основные таблицы регистров разбиты на секции с учетом файловых групп базы данных. Но для чего мы все это делали и что делать дальше?
Итак, поехали!
Какие проблемы решает
Выше мы настроили секционирование и даже проверили работает ли оно. Данные таблиц и индексов были распределены между файловыми группами (в нашем случае фактически между отдельными файлами), но какая от этого польза? Далее мы рассмотрим несколько простых кейсов, когда секционирование Вам может помочь.
Гибкое управление данными
В нашем примере есть три секции + одна стандартная. Предположим, что первая секция, хранящая данные регистров до 2011 года, должна сохраняться в системе в качестве архивных данных, при этом нужно снизить затраты дискового пространства для нее.
Поскольку к этим данным выполняется редкое обращение, то можно использовать сжатие PAGE для таблицы и индексов на этой секции. Сэкономим место на архивных данных, при этом сохраним уровень производительности при работе с остальными секциями (использование сжатия требует доп. ресурсов CPU).
ALTER INDEX _AccumRg84_1-- При указании секции для сжатия обязательно-- указывать перестроение всех секций (REBUILD PARTITION=ALL )ON _AccumRg84 REBUILD PARTITION=ALL-- При сжатии указываем номер секцииWITH (DATA_COMPRESSION = PAGE ON PARTITIONS(1))
Проверим результат с помощью этого скрипта.
| Таблица | Объект | Номер секции | Сжатие |
|---|---|---|---|
| _AccumRg84 | _AccumRg84_1 | 1 | PAGE |
| _AccumRg69 | _AccumRg69_1 | 1 | PAGE |
Кроме сжатия, для отдельных секций доступны:
- Перенос данных, что может быть актуальным при переносе данных из OLTP в OLAP
- Операции обслуживания
- Операции бэкапирования
- И др.
Тема обширная и рассмотреть ее в одной публикации невозможно, поэтому если Вам это интересно, то рекомендую почитать MSDN.
Повышение эффективности дисковой подсистемы
Секции могут храниться на отдельных дисках, что позволит увеличить пропускную способность дисковой подсистемы при работе с ними, ускорит получение и запись данных.
Например, есть две файловые группы FG1 и FG2, которые используют два отдельных файла. У нас простой пример и все файлы находятся в одном каталоге, на одном диске. Но никто не мешает распределить файлы по разным дискам, тем самым ускорив операции ввода-вывода с ними. Подобный подход разбиения базы по дисковой подсистеме может дать значительный прирост производительности в зависимости от назначения системы и выполняемых в ней SQL-запросов.
Часто даются рекомендации по переносу базы tempdb на отдельный диск для улучшения производительности, т.к. это позволяет снизить конкуренцию за дисковые ресурсы между основной базой данных и tempdb. Представьте какие возможности у Вас появятся для оптимизации операций ввода-вывода, если основную базу можно будет расположить на нескольких дисках.
Оптимизация стратегии бэкапирования
В этом случае все сводится к простому правилу - бэкапировать нужно лишь то, что меняется. Если файловая группа FG1 не меняется уже 6 лет, то зачем делать ее регулярный бэкап?

Вместо этого можно оптимизировать стратегию бэкапирования, делая резервную копию только “свежих” данных. В нашем случае для файловой группы FG1 можно установить режим “Только для чтения”, чтобы в ней никто не смог поменять данные, в т.ч. и через 1С.
USE [Partitioning]GOdeclare @readonly bitSELECT @readonly=convert(bit, (status & 0x08))FROM sysfilegroups WHERE groupname=N'FG1'if(@readonly=0)ALTER DATABASE [Partitioning] MODIFY FILEGROUP [FG1] READONLYGO
Теперь при попытке изменить данные в старом периоде через 1С появится ошибка на уровне СУБД. Это необходимо учитывать и делать проверки на уровне решения 1С.
Вернемся к формированию бэкапа. Допустим, изначально для базы использовалась полная модель бэкапирования, ежедневно ночью был настроен бэкап полный и лога транзакции каждые 30 минут. Появилась проблема, что из-за большого объема базы полный бэкап выполняется длительное время и мешает работе пользователей и регламентных заданий. Примерный скрипт для формирования полного бэкапа может быть таким.
BACKUP DATABASE [Partitioning]TO DISK = N'D:\DBs\Backup\Partitioning.bak'WITH NOFORMAT, NOINIT,NAME = N'Partitioning-Полная База данных Резервное копирование',SKIP, NOREWIND, NOUNLOAD, COMPRESSION, STATS = 10, CHECKSUMGO
Вместо этого сделаем резервное копирование только тех данных, что могут меняться, а файловую группу FG1 в режиме “Только для чтения” исключим из резервной копии. Предполагается, что резервная копия файловой группы FG1 уже есть и ее повторное создание не имеет смысла.
BACKUP DATABASE [Partitioning]-- Перечисляем файловые группы для создания резервной копииFILEGROUP = N'PRIMARY',FILEGROUP = N'FG2',FILEGROUP = N'FG3'TO DISK = N'D:\DBs\Backup\Partitioning.bak' WITH NOFORMAT,NOINIT,NAME = N'Partitioning-Полная База данных Резервное копирование',SKIP, NOREWIND, NOUNLOAD, COMPRESSION, STATS = 10, CHECKSUMGO
Конечно, работать с такими бэкапами нужно немного иначе, но особых проблем с восстановлением данных не будет. Например, если была повреждена архивная файловая группа FG1, то ее восстановить проще всего, т.к. установлен режим только для чтения.
RESTORE DATABASE [Partitioning]FILE = N'Partitioning_FG1'FROM DISK = N'D:\DBs\Backup\FG1.bak'WITH FILE = 1, NOUNLOAD, STATS = 10GO
В случае необходимости восстановления данных из остальных файловых групп и логов транзакций скрипт может быть таким.
USE [master]-- Создаем резервную копию заключительного фрагмента журнала транзакции-- и устанавливаем состояние базы в "NORECOVERY"BACKUP LOG [Partitioning] TO DISK = N'D:\DBs\Backup\Last_LogBackup.bak'WITH NOFORMAT, NOINIT, NAME = N'Last_LogBackup',NOSKIP, NOREWIND, NOUNLOAD, NORECOVERY , STATS = 5-- Восстанавливаем состояние базы на указанный момент времени (параметр STOPAT)RESTORE DATABASE [Partitioning] FROM DISK = N'D:\DBs\Backup\WeeklyBackup.bak'WITH FILE = 1, NORECOVERY, NOUNLOAD, STATS = 5RESTORE LOG [Partitioning] FROM DISK = N'D:\DBs\Backup\LogBackup1.trn'WITH FILE = 1, NORECOVERY, NOUNLOAD, STATS = 5RESTORE LOG [Partitioning] FROM DISK = N'D:\DBs\Backup\LogBackup2.trn'WITH FILE = 1, NOUNLOAD, STATS = 5,STOPAT = N'2019-02-08T16:15:13' -- Момент времени для восстановленияGO
Тема стратегии бэкапирования достаточно обширна, всю ее рассматривать здесь не будем.
Что может быть лучше, чем быстрый бэкап :)
Улучшение процедур обслуживания
Для ускорения процедур обслуживания индексов и статистик можно выполнять операции на отдельных секциях.
Например, у нас есть 4 секции, причем одна из них вообще в режиме “Только для чтения”. Чтобы уменьшить время обслуживания можно применить скрипт только к последней, “горячей” секции.
USE [Partitioning]GOALTER INDEX [_AccumRg69_1] ON [dbo].[_AccumRg69]-- Указание конкретной секции для перестроения-- В обычных ситуациях выполняется перестроение всех-- секций, что аналогично указанию "REBUILD PARTITION = ALL"REBUILD PARTITION = 4GO
Окей, с индексами все понятно, но как же статистика? Иногда обслуживание всех статистик может занимать даже больше времени, чем обслуживание индексов. При этом гистограмма распределения значений по таблице / индексу, чем в принципе и является статистика, не рассчитывается для каждой отдельной секции. Но решение все же есть. Начиная с версии SQL Server 2014 появилась так называемая инкрементальная статистика, которая может пересчитываться по секциям.
По умолчанию объекты базы данных не поддерживают инкрементальную статистику, потому что платформа 1С не включает их явно. Включить данный вид статистики для индекса можно при создании / перестроении.
CREATE UNIQUE CLUSTERED INDEX [_AccumRg69_1] ON [dbo].[_AccumRg69]([_Period] ASC,[_RecorderRRef] ASC,[_LineNo] ASC-- Включение инкрементальной статистики для индекса-- Кстати, мы это уже делали в одном из предыдущих скриптов :))WITH (DROP_EXISTING = ON, STATISTICS_INCREMENTAL = ON)ON [ByDatePartitionScheme](_Period)GO
Для того, чтобы выполнить пересчет для конкретной секции нужно воспользоваться следующим приемом.
UPDATE STATISTICS [dbo].[_AccumRg69]([_AccumRg69_1])-- Указываем конкретную секцию для обновления статистикиWITH RESAMPLE ON PARTITIONS(4);
Для подробной информации о работе инкрементальной статистики и ее “внутренней кухне” рекомендую изучить статью “SQL Server 2014 : New incremental statistics”, а также на MSDN. В них есть подробное описание как работает инкрементальная статистика, в каких случаях ее стоит использовать, ограничения и др. Если у Вас в базе огромные таблицы, то инкрементальная статистика может быть настоящим спасением при оптимизации обслуживания.

Подобные подходы актуальны для очень больших таблиц. На сколько это ускорит обслуживание? Ответ на этот вопрос можете дать только Вы, проанализировав объем данных и возможности своей инфраструктуры. К сожалению, инкрементальная статистика не решает проблему снижения эффективности статистики при росте таблиц, но это уже другая история (если интересно, то можно написать в других статьях).
Проблемы блокировок
С тех пор, как платформа использует свой “костыль” в виде менеджера управляемых блокировок и режим изоляции транзакций Read Commited Snapshot Isolation (RCSI), то проблемы блокировок на уровне SQL Server стало значительно меньше. Однако проблема эскалации блокировок все еще актуальна, т.к. она не решается использованием управляемых блокировок.
Проблема заключается в том, что при модификации большого объема данных таблицы в рамках одной транзакции SQL Server для оптимизации использования памяти может укрупнить область блокировки до уровня секции таблицы или всей таблицы.
Подробно этот пункт рассматривать не будем. Скажу лишь кратко, что с помощью секций можно снизить влияние эскалации блокировок. Вместо блокировки на всю таблицу может быть заблокирована одна секций, но это грубое описание.
Плюсы и минусы
Все имеет свои плюсы и минусы, и секционирование тут не исключение.
Плюсы:
- Гибкое управление данными, за счет действий над отдельными секциями (сжатие, перенос на отдельный диск, перенос данных на другие инстансы, бэкапирование и др.)
- Ускорение операций обслуживания (перестроение индексов и обновление статистик по секциям).
- Повышение производительности запросов для некоторых ситуаций. Эту ситуацию мы не рассматривали, но происходит это за счет:
- Исключение обращений к секциям, которые не соответствую фильтрам запроса.
- За счет разнесения секций на отдельные диски.
Минусы:
- Сложность администрирования и поддержки, т.к. требуются дополнительные компетенции.
- Cложность при разработке баз данных, т.к. секционирование должно учитываться при модификации базы.
- Как ни странно, секционирование может вызвать проблемы производительности в некоторых запросах. Например, из-за дополнительной операции соединения наборов данных из разных секций. Это стоит учитывать при планировании инфраструктуры и написания SQL-запросов.
Мы не будем отдельно останавливаться на каждом пункте, т.к. тогда статья станет очень большой и превратиться в книгу.. Более подробную информацию Вы всегда можете узнать на MSDN. Главное что нужно понять, что секционирование не является простым решением, поэтому перед его использованием нужно взвесить все плюсы и минусы. Особенно это важно в контексте платформы 1С, где нет полной власти над базой данных (она как бы есть, но ее как бы нет :)).
Проблемы в мире 1С
В контексте платформы 1С секционирование имеет свои особенности и подводные камни, а именно:
- Лицензионное соглашение фирмы “1С” запрещает использовать недокументированные возможности. Только Вы ответственны за то, что делаете. Сам факт нарушения соглашения может как минимум вылиться в отказ в технической поддержки.
- Проблемы при обновлении конфигурации, а именно реструктуризации таблиц.
- Поскольку платформа 1С ничего не знает о секциях, то при реструктуризации все настройки таблиц и индексов будут сброшены на стандартные и секции будут “затерты”.
- При обновлении платформы 1С на новую версию или отказ от совместимости в конфигурации может привести к значительным изменениям на уровне базы, что может противоречить сделанными Вами изменениям. Например, ранее платформа хранила тип “Хранилище значений” с помощью SQL-типа “IMAGE”. В одной из версий платформы этот тип был заменен на “VARBINARY”. Если такие ситуации не обнаружить, то в лучшем случае реструктуризация прервется с ошибкой, а в худшем случится потеря данных.
- Архитектура таблиц метаданных в большинстве решений противоречит основным требованиям секционирования.
- Типовые конфигурации в большинстве таблиц имеют разделитель данных с типом “numeric”, который включен во все индексы. Если Вы используете разделитель, то может понадобиться секционировать не просто по периоду, а по периоду с учетом разделителя. Проблема в том, что SQL Server поддерживает только указание одного поля секционирования. Решение тут - создавать виртуальное поле, о котором 1С ничего знать не будет, но этот подход мы сейчас не будем описывать. Если кому-то интересно - пишите в комментариях.
- Не все типовые индексы можно просто так взять и секционировать, потому что не все они содержат поле секционирования, а это обязательное условие. Выше был пример, когда для включения секционирования пришлось добавлять поле “Период” в индекс по регистратору.
- И многие другие специфические проблемы, с которыми можно столкнуться.
- Топорное построение SQL-запросов платформой “1С” сводит на нет выигрыш в производительности для запросов по большим таблицам. Например, выше выполнено секционирование таблицы “_AccumRg84”. Обслуживание ускорили, архивные данные сжимаем и поставили только для чтения, а бэкапы теперь выполняются гораздо быстрее. Но вот исключение обращений к архивным секциям в запросах не работает. Выполняя такой запрос из 1С мы ожидали, что будет прочитана только секция в файловой группе “PRIMARY”. Вот текст запроса и план его выполнения.exec sp_executesql N'SELECTCAST(COUNT_BIG(T1._RecorderRRef) AS NUMERIC(12))FROM dbo._AccumRg84 T1WHERE ((T1._Period >= @P1) AND (T1._Period <= @P2))'-- Все даты преобразуются к типу datetime2(3),-- фактически период хранится с типом datetime2(0),N'@P1 datetime2(3),@P2 datetime2(3)','4019-01-01 00:00:00','4019-01-31 23:59:59'
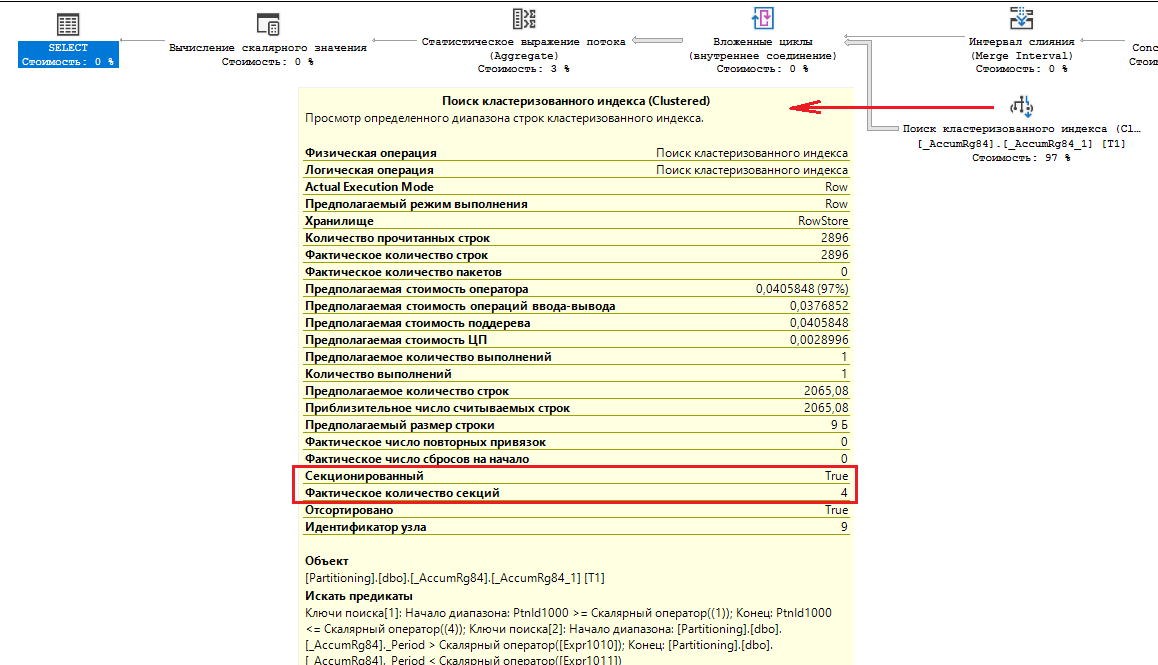
Обратите внимание, что запрос секционированный и фактически обработано 4 секции, что не правильно. Все дело в том, что платформа по неведомой причине преобразовывает все параметры дат в SQL-запросах к типу “datetime(3)”, хотя в таблицах даты хранятся с типом “datetime(0)”. Для SQL Server это важно, т.к. происходит неявное преобразование типов и СУБД не может использовать секции. Если убрать преобразование дат и сразу поставить нужный тип “datetime(0)”, то ситуация кардинально изменяется.
exec sp_executesql N'SELECTCAST(COUNT_BIG(T1._RecorderRRef) AS NUMERIC(12))FROM dbo._AccumRg84 T1WHERE ((T1._Period >= @P1) AND (T1._Period <= @P2))'-- Убираем преобразование типов к datetime2(3),N'@P1 datetime2(0),@P2 datetime2(0)','4019-01-01 00:00:00','4019-01-31 23:59:59'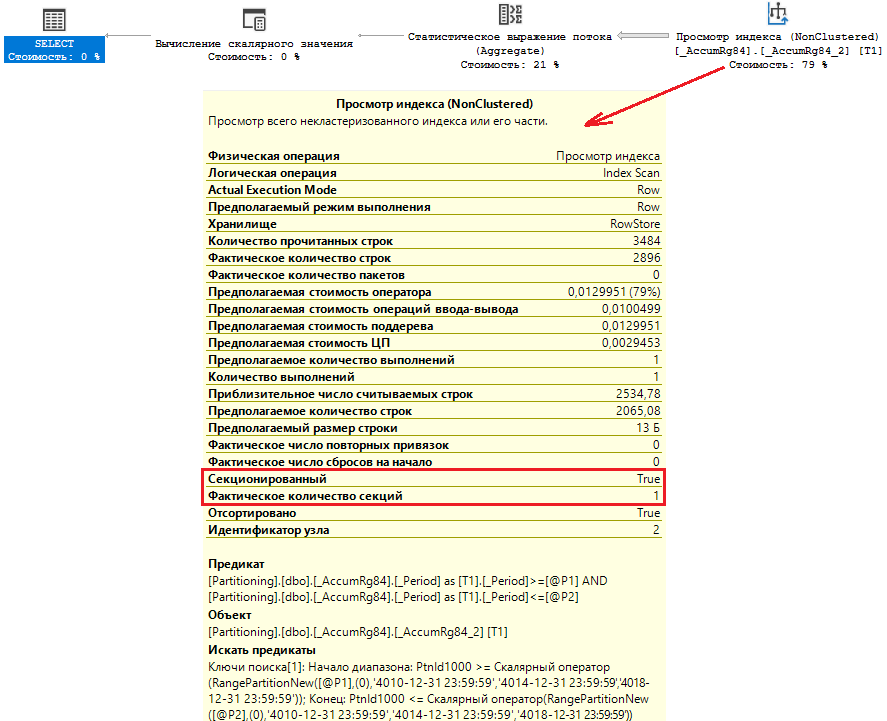
Как можно заметить, запрос остается секционированным, но прочитана всего 1 секция. Это может быть критическим для больших операций чтения, например для Table Scan. Ведь прочитать одну секцию вместо 4 все же лучше.
Первую проблему с лицензионным соглашением мы решить не в силах, можно с ней только жить и принять. Проблему с архитектурой таблиц метаданных и особенными запросами платформы решить можно, но это уже выходит за рамки статьи. Ниже лишь кратко продемонстрируем решение проблемы с реструктуризациями, чтобы в один прекрасный момент не потерять секции. Если Вам интересно как исправить запросы платформы 1С или архитектуру таблиц метаданных на стороне БД пишите в комментариях, может это будет стимул для новой статьи.
Костыли и палки
В статье “Создаем свои индексы для баз 1С. Со своей структурой и настройками!” мы говори про создание и поддержку неплатформенных индексов для баз 1С. Для решения проблем удаления собственных индексов при реструктуризации использовались глобальные триггеры, перехватывающие события создания таблиц и индексов платформой и добавляющие свои нужные действия (создание индексов, изменение параметров индексов и таблиц и др.).
Этот же подход подойдет и для сохранения настроек секционирования, но с некоторыми особенностями.
CREATE TRIGGER [CustomSettingsMaintenance_OnIndexCreate]ON ALL SERVERAFTER CREATE_INDEXASBEGINSET NOCOUNT ON;-- В случае возникновения ошибок продолжаем работуSET XACT_ABORT OFF;DECLARE @SchemaName SYSNAME,@TableName SYSNAME,@DatabaseName SYSNAME,@IndexName SYSNAME;SELECT @TableName = EVENTDATA().value('(/EVENT_INSTANCE/TargetObjectName)[1]','SYSNAME')SELECT @SchemaName = EVENTDATA().value('(/EVENT_INSTANCE/SchemaName)[1]','SYSNAME')SELECT @IndexName = EVENTDATA().value('(/EVENT_INSTANCE/ObjectName)[1]','SYSNAME')SELECT @DatabaseName = EVENTDATA().value('(/EVENT_INSTANCE/DatabaseName)[1]','SYSNAME');-- Здесь запускаем скрипт перестроения индекса с учетом схемы секционирования-- Для индексов, которые не содержат поле секционирования, также выполняем-- их перестроение с добавлением этого поля. Если необходимо, то-- включаем инкрементальную статистику.-- Дополнительно можно учитывать файловые группы только для чтения и отключать-- эту настройку на время реструктуризации.-- Возвращаем значение по умолчанию для ситуаций с ошибками в транзакцииSET XACT_ABORT ON;END
С помощью глобального триггера отлавливаем события изменения индексов и перестраиваем их с учетом параметров секционирования. Подробнее об этом подходе можно прочитать на GitHub.
Это конец
Вот и все. На самом деле ничего сложного, если понимать для чего это нужно.
Нужно ли это использовать на практике? Решать только Вам, но если хоть один из пунктов к Вам относится, то секционирование точно не для Вас:
- Используется файловый режим работы информационной базы
- Нет никаких проблем производительности и стабильности информационной системы
- Считаете большой ошибкой выход за пределы экосистемы платформы 1С
- Вы сотрудник фирмы “1С”
В случае если у Вас высоконагруженная база, то рассмотреть возможность секционирования стоит, но делать это должен либо эксперт, либо архитектор 1С вместе с DBA.