Как разбить базу на файлы и не сойти с ума
#SQL Server
#1С:Предприятие
#файловые группы
#базы данных
#файлы
Суть вопроса
В прошлых статьях мы уже говорили о подходах к разработке и обслуживанию базы данных, которые позволяют использовать индексы произвольной структуры и даже секционирование для баз 1С. Казалось бы, тема исчерпана и для высоконагруженных баз может наступить светлое будущее, не смотря на то, что платформа 1С пока так и не поддерживает эти возможности из “коробки”.
Однако, хотелось бы остановиться подробнее на такой теме как разбиение базы данных на отдельные файлы с помощью файловых групп. В статье про секционирование файловые группы уже использовались для секций, но там про них был сказано вскользь.
Сегодня мы более детально рассмотрим их использование, а также нюансы, с которыми нужно считаться при обслуживании базы данных, реструктуризациях и других моментах.
Для чего вообще может понадобиться разбивать базу данных на отдельные файлы? Самые распространенные кейсы:
- Есть регистр сведений, в котором хранятся двоичные данные файлов. Необходимо вынести хранение файлов на отдельный диск / хранилище, чтобы освободить место на быстрых дисках.
- Есть старые архивные таблицы, которые уже редко используются, но удалять данные нельзя. Почему бы такие таблицы также не перенести на отдельные диски, которые для этого и предназначены. Тем более такие файловые группы можно сделать только для чтения.
- Ускорить бэкапирование базы, т.к. архивные файловые группы можно не бэкапировать каждый раз. Они ведь не меняются!
- Улучшение производительности, за счет распределения файлов базы данных на отдельные носители.
Тему ускорения бэкапирования и производительности сейчас мы рассматривать не будем, но Вы можете прочитать об этом в публикации про секционирование. Сосредоточимся на описании настроек для файловых групп и их сопровождении. Все примеры ниже будут сделаны для SQL Server, но и для PostgreSQL это будет работать с некоторыми модификациями.
Стандартный подход
Любая база, будь то для 1С или любого другого приложения, поддерживает разбиение базы на несколько файлов (конечно, если это поддерживает СУБД). В контексте SQL Server это реализуется с помощью файловых групп.
По умолчанию база содержит лишь одну файловую группу “PRIMARY”, которую 1С и использует для своих целей. Кроме таблиц и индексов в этой предопределенной группе хранится служебная информация о базе, различные заголовки и др., поэтому полностью заменить эту группу на другую нельзя, она всегда будет присутствовать.
Однако, мы можем добавить собственные файловые группы и использовать их для 1С\’ных таблиц, причем сама платформа об этом не узнает.
Возьмем для примеров демобазу БСП и создадим в ней две новых файловых группы.
-- В примере имя базы данных на сервере СУБД имеет название "bsl"USE [master]GOALTER DATABASE [bsl] ADD FILEGROUP [FILEGROUP_2]GOALTER DATABASE [bsl] ADD FILEGROUP [FILEGROUP_3]GO
Но просто добавить файловые группы недостаточно. Еще нужно добавить файлы данных, для которых эти файловые группы будут задействованы.
-- Оставляем стандартные параметры инициализации файлов, для нашего примера это не критично.-- Все файлы базы данных находятся в каталоге "D:\DBs"-- Добавляем файлы для файловых группALTER DATABASE [bsl]ADD FILE ( NAME = N'bsl_fg_2', FILENAME = N'D:\DBs\bsl_fg_2.mdf' , SIZE = 8192KB , FILEGROWTH = 65536KB )TO FILEGROUP [FILEGROUP_2]GOALTER DATABASE [bsl]ADD FILE ( NAME = N'bsl_fg_3', FILENAME = N'D:\DBs\bsl_fg_3.mdf' , SIZE = 8192KB , FILEGROWTH = 65536KB )TO FILEGROUP [FILEGROUP_3]GO
Отлично, у нас есть две файловые группы “FILEGROUP_2” и “FILEGROUP_3”, осталось их задействовать. Есть несколько основных вариантов:
- Мы можем вручную изменить основную файловую группу базы и сделать реструктуризацию средствами 1С.
- Мы можем пересоздать кластерный или другие индексы средствами T-SQL, указав для использования нужную файловую группу.
- Ничего не делать.
По третьему варианту написано довольно много примеров в сети, поэтому рассмотрим только первые два пункта. Все примеры будем делать на регистре сведений “История адресных объектов”, который на стороне базы представлен таблицей “_InfoRg4683” с несколькими индексами.
Вперед через реструктуризацию
И так, для начала установим основную файловой группой - одну из тех, что добавили выше.
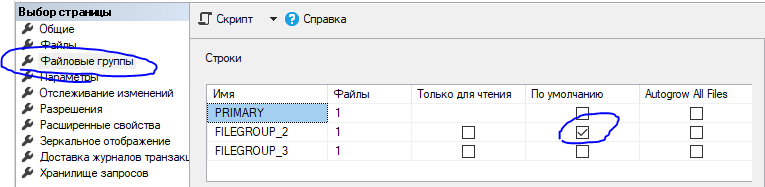
То же самое можно сделать через T-SQL. Кому как больше нравится.
USE [bsl]GOIF NOT EXISTS (SELECT name FROM sys.filegroups WHERE is_default=1 AND name = N'FILEGROUP_2')ALTER DATABASE [bsl] MODIFY FILEGROUP [FILEGROUP_2] DEFAULTGO
Теперь нужно сделать реструктуризацию средствами платформы. Нормального способа вызвать ее для нашего случая нет, но мы можем:
- Добавить временно реквизит в таблицу, а потом запустить реструктуризацию.
- Полностью реструктуризировать базу через “Тестирование и исправление”.
Оба варианта выглядят “не очень”, и Вам повезет, если необходимость реструктуризации появится как-раз в этот момент для других задач. При использовании инструмента “Тестирование и исправление” Вы вообще переведете все таблицы и индексы в установленную файловую группу, поэтому этот случай мы вообще рассматривать не будем. А вот пример с добавлением временного реквизита - пожалуйста.
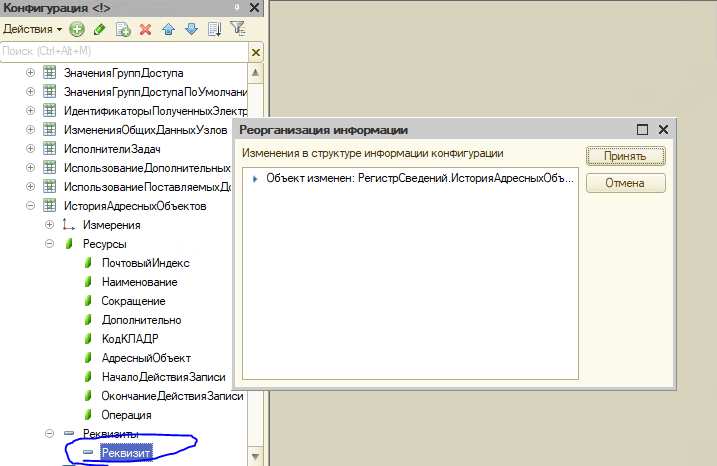
С помощью этих скриптов можно узнать как изменилась структура базы в части использования файловых групп. Вот какие изменения мы получили.
| Таблица | Индекс | Файловая группа | Файл |
|---|---|---|---|
| _InfoRg4683 | _InfoRg4683_ByDims_NNNNNNNNNNBN | FILEGROUP_2 | D:\DBs\bsl_fg_2.mdf |
| _InfoRg4683 | _InfoRg4683_ByResource4705_SNNNNNNNNNNBN | FILEGROUP_2 | D:\DBs\bsl_fg_2.mdf |
| _InfoRg4683 | _InfoRg4683_ByDims_NNNNNNNNNNBN | FILEGROUP_2 | D:\DBs\bsl_fg_2.mdf |
| _InfoRg4683 | _InfoRg4683_ByDims_NNNNNNNNNNBN | FILEGROUP_2 | D:\DBs\bsl_fg_2.mdf |
Таким образом, мы перевели таблицу регистра сведений “История адресных объектов” и все ее индексы в файловую группу “FILEGROUP_2”.
Подведем итог по данному способу.
Плюсы:
- Простота в настройке
Минусы:
- Нужен вызов платформенной реструктуризации, что не всегда оптимально. После реструктуризации надо обратно настраивать основную файловую группу.
- Необходимость проводить реструктуризацию таблиц в разных файловых группах отдельно друг от друга, что не всегда возможно.
Вообщем, способ неэффективный, но требует минимальных действий на стороне СУБД.
Скриптуем
Более эффективный и гибкий подход - это перенос таблиц и индексов в другую файловую группу с помощью скриптов. Вот так будет выглядеть скрипт для переноса всех индексов регистра сведений “История адресных объектов” в третью файловую группу.
Фактически, нам нужно пересоздать индексы с указанием новой файловой группы. При этом, когда мы пересоздаем кластерный индекс таблицы, то все данные в ней переносятся в новую файловую группу.
USE [bsl]GOCREATE UNIQUE CLUSTERED INDEX [_InfoRg4683_ByDims_NNNNNNNNNNBN] ON [dbo].[_InfoRg4683]([_Fld4684] ASC,[_Fld4685] ASC,[_Fld4686] ASC,[_Fld4687] ASC,[_Fld4688] ASC,[_Fld4689] ASC,[_Fld4690] ASC,[_Fld4691] ASC,[_Fld4692] ASC,[_Fld4693] ASC,[_Fld4694] ASC,[_Fld4695] ASC)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = ON, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)ON [FILEGROUP_3] -- Задаем имя новой файловой группыGOCREATE NONCLUSTERED INDEX [_InfoRg4683_ByMainFilter_NNNNNNNNNNNB] ON [dbo].[_InfoRg4683]([_Fld4684] ASC,[_Fld4685] ASC,[_Fld4686] ASC,[_Fld4687] ASC,[_Fld4688] ASC,[_Fld4689] ASC,[_Fld4690] ASC,[_Fld4691] ASC,[_Fld4692] ASC,[_Fld4693] ASC,[_Fld4695] ASC,[_Fld4694] ASC)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = ON, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)ON [FILEGROUP_3] -- Задаем имя новой файловой группыGOCREATE UNIQUE NONCLUSTERED INDEX [_InfoRg4683_ByResource4705_SNNNNNNNNNNBN] ON [dbo].[_InfoRg4683]([_Fld4697] ASC,[_Fld4684] ASC,[_Fld4685] ASC,[_Fld4686] ASC,[_Fld4687] ASC,[_Fld4688] ASC,[_Fld4689] ASC,[_Fld4690] ASC,[_Fld4691] ASC,[_Fld4692] ASC,[_Fld4693] ASC,[_Fld4694] ASC,[_Fld4695] ASC)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = ON, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)ON [FILEGROUP_3] -- Задаем имя новой файловой группыGOCREATE UNIQUE NONCLUSTERED INDEX [_InfoRg4683_ByResource4706_SNNNNNNNNNNBN] ON [dbo].[_InfoRg4683]([_Fld4698] ASC,[_Fld4684] ASC,[_Fld4685] ASC,[_Fld4686] ASC,[_Fld4687] ASC,[_Fld4688] ASC,[_Fld4689] ASC,[_Fld4690] ASC,[_Fld4691] ASC,[_Fld4692] ASC,[_Fld4693] ASC,[_Fld4694] ASC,[_Fld4695] ASC)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = ON, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)ON [FILEGROUP_3] -- Задаем имя новой файловой группы
Для того, чтобы сгенерировать скрипты создания индексов, можно воспользоваться стандартными возможностями SQL Managment Studio по созданию скриптов для базы данных.
Все, теперь мы счастливые обладатели регистра сведений, который находится в дополнительной файловой группе. Смотрим итог с помощью этих скриптов.
| Таблица | Индекс | Файловая группа | Файл |
|---|---|---|---|
| _InfoRg4683 | _InfoRg4683_ByDims_NNNNNNNNNNBN | FILEGROUP_3 | D:\DBs\bsl_fg_3.mdf |
| _InfoRg4683 | _InfoRg4683_ByResource4705_SNNNNNNNNNNBN | FILEGROUP_3 | D:\DBs\bsl_fg_3.mdf |
| _InfoRg4683 | _InfoRg4683_ByDims_NNNNNNNNNNBN | FILEGROUP_3 | D:\DBs\bsl_fg_3.mdf |
| _InfoRg4683 | _InfoRg4683_ByDims_NNNNNNNNNNBN | FILEGROUP_3 | D:\DBs\bsl_fg_3.mdf |
Как итог, определим плюсы и минусы.
Плюсы:
- Быстрый и эффективный способ работы с файловыми группами.
- Нет необходимости каких-либо действий на стороне 1С.
Минусы:
- Нет связи с платформой 1С, даже призрачной как в прошлом примере.
Конечно, предпочтительнее использовать этот способ, если Вы бережете время, нервы и деньги.
Сложности для 1С
Все выглядит просто, но есть нюансы.
Во-первых, лицензионное соглашение 1С запрещает так работать с СУБД, т.к. эти возможности недокументированы. Начиная использовать файловые группы, Вы должны осознавать риски нарушения этого соглашения. Минимальные последствия - это отказ в технической поддержке решений на платформе 1С.
В пункте 65 лицензионного соглашения сказано следующее:
Лицензионное соглашение не позволяет использовать недокументированные фирмой "1С" средства для построения решений на платформе "1С:Предприятие". Это означает, что средства СУБД (или любые другие внесистемные средства) можно использовать только в том случае, если документация по продуктам линейки "1С:Предприятие" (включая 1С:ИТС) содержит явную рекомендацию использовать данное средство для решения данной задачи.Во всех остальных случаях лицензионное соглашение позволяет использовать для построения решений только штатные средства платформы. В частности, можно обращаться к данным информационной базы только при помощи объектов "1С:Предприятия", специально предназначенных для работы с данными (запросы, справочники, документы и т. д.). Нельзя обращаться к данным информационной базы напрямую, минуя уровень объектов работы с данными "1С:Предприятия", например при помощи средств СУБД или при помощи внешних компонент, которые реализуют прямой доступ к СУБД. Это ограничение распространяется на любые действия с данными, в том числе на изменение их структуры, а так же на чтение или изменение самих данных информационной базы или служебных данных "1С:Предприятия".Данное ограничение необходимо для обеспечения стабильности работы механизмов системы, осуществления поддержки и возможности перехода на новые версии "1С:Предприятия".
Вы должны четко понимать плюсы и минусы данного шага. Все, что Вы сделаете будет на Вашей совести!
Во-вторых, это усложнение сопровождения, т.к. при обновлении базы данных необходимо учитывать тот факт, что некоторые таблицы находятся в других файловых группах или дисковых носителях.
Зачем это учитывать? Например, у Вас в базе есть регистр сведений “Присоединенные файлы” (в базе представлен таблицей “_InfoRg2133”), в котором хранятся двоичные данные разнотипных документов. Для экономии места в основном хранилище данных был выполнен перенос этих документов в отдельную файловую группу. Файл данных для нее находится на отдельном диске.
Платформа 1С хранит двоичные данные документов в LOB-типах данных (image или varbinary(max) в зависимости от версии платформы). Для переноса LOB-данных в отдельную файловую группу не обязательно переносить всю таблицу и индексы. Достаточно перенести только сами LOB-данные, указав основную файловую группу для таких типов. Именно так мы и сделаем в примере ниже.
-- Создаем таблицу с новыми настройками хранения LOB-данных,-- при этом структура таблица полностью поторяет структуру исходной-- таблицы регистра сведений "Присоединенные файлы"CREATE TABLE dbo.Tmp__InfoRg2133(_Fld2134_TYPE binary(1) NOT NULL,_Fld2134_RTRef binary(4) NOT NULL,_Fld2134_RRRef binary(16) NOT NULL,_Fld2135 image NOT NULL,_Fld2683 numeric(7, 0) NOT NULL) ON [PRIMARY]-- !!! Именно здесь необходимо указать файловую группу,-- !!! в которой будут храниться двоичные данные документовTEXTIMAGE_ON FILEGROUP_3GO-- Для оптимизации устанавливаем уровень эскалации блокировок = ТаблицаALTER TABLE dbo.Tmp__InfoRg2133 SET (LOCK_ESCALATION = TABLE)GO-- Переносим данные из старой таблицы в новуюIF EXISTS(SELECT * FROM dbo._InfoRg2133)EXEC('INSERT INTO dbo.Tmp__InfoRg2133 (_Fld2134_TYPE, _Fld2134_RTRef, _Fld2134_RRRef, _Fld2135, _Fld2683)SELECT _Fld2134_TYPE, _Fld2134_RTRef, _Fld2134_RRRef, _Fld2135, _Fld2683 FROM dbo._InfoRg2133 WITH (HOLDLOCK TABLOCKX)')GO-- Удаляем старую таблицуDROP TABLE dbo._InfoRg2133GO-- Новой таблице присваиваем то же самое имя, что было у исходнойEXECUTE sp_rename N'dbo.Tmp__InfoRg2133', N'_InfoRg2133', 'OBJECT'GO-- Далее создаем недостающие индексы. Все аналогично исходной таблицеCREATE UNIQUE CLUSTERED INDEX _InfoRg2133_ByDims_R ON dbo._InfoRg2133(_Fld2683,_Fld2134_TYPE,_Fld2134_RTRef,_Fld2134_RRRef) WITH( STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]GO
Теперь все LOB-данные перенесены в файловую группу “FILEGROUP_3”. При необходимости основной файл данных, где ранее хранились перемещенные документы, можно уменьшить операцией Shrink. В нашем случае мы это рассматривать не будем.
Не забудьте сделать бэкап перед такими операциями. Этот скрипт не является готовым решением. Его можно улучшить за счет различных проверок, транзакций и т.д.
Все отлично сработало, мы освободили 1 ТБ данных в основном хранилище. НО! В один прекрасный день разработчики 1С внесли изменения в систему, добавив новый ресурс к регистру сведений “Присоединенные файлы”. В тестовых базах все проверено, ведь там никто не держит полную копию рабочей базы. Изменение ушло в релиз, но при развертывании возникли следующие проблемы:
- в хранилище, где находится основной файл базы данных, не хватило места при выполнении реструктуризации. Ведь в процессе платформа создает таблицу заново в основной файловой группе базы, то есть в “PRIMARY”. Получается, что платформа создала таблицу и “перегоняла” в нее данные из файловой группы “FILEGROUP_3”, пока не заполнила диск.
- Из-за прерванной с ошибкой реструктуризации в базе данных (в файловой группе “PRIMARY”) останется таблица “_InfoRg2133NG”, в которую платформа и “переливала” данные. Чтобы исправить ситуацию и освободить место ее нужно будет удалить вручную. Не будем останавливаться на описании процесса реструктуризации, лишь отметим, что платформа добавляет к пересоздаваемым таблицам постфикс “NG”. Так Вы можете в базе найти таблицы, которые появились при “битой” реструктуризации базы данных.
- Исправить последствия попытки реструктуризации может быть не просто, ведь для этого нужно выполнить шринк основного файла данных, а это может быть очень длительной и ресурсоемкой операцией. Да, в прошлом пункте мы удалили таблицу, но файл данных от этого не уменьшился в размере. Мы лишь освободили место в самом файле данных.
В итоге, если такая ситуация произойдет и добрые администраторы не смогут выделить дополнительное место да дисках, то может произойти остановка работы системы. Но это не точно и полностью зависит от Вашей инфраструктуры!
Но есть ли способ избавиться от такой проблемы? Да, есть! Вот несколько рекомендаций:
- Проверять перечень таблиц для реструктуризации перед каждым релизом.
- В случае, если изменения затронули тяжелые таблицы, для которых применены нестандартные файловые группы, то один из вариантов:
- Отказаться от изменения на этой таблице. Вместо этого использовать внешние таблицы. Например, вместо добавления реквизита в справочник можно добавить его как доп. свойство или в дополнительный регистр сведений. Включите воображение!
- Если изменения все же очень нужны, то необходимо делать реструктуризацию в “ручном режиме”. Подробнее останавливаться на этом сейчас не будем, но на ИС уже об этом писали. Причем, чем больше изменений, тем и сложнее будет сделать это вручную.
- Максимально автоматизировать настройку файловых групп для таблиц и индексов базы, а также сделать заглушки для тех таблиц, где реструктуризация автоматически проходить не должна. Об этом будет ниже.
В этом и кроются основные причины усложнения сопровождения. Поэтому стоит 7 раз подумать, прежде чем начать такое у себя использовать.
Автоматизируй это!
Выше мы упомянули про автоматизацию настроек файловых групп для таблиц и индексов. На самом деле здесь ничего нового нет и используется тот же самый подход по созданию произвольных индексов и применению настроек сжатия, что был в статье “Создаем свои индексы для баз 1С. Со своей структурой и настройками!”. Он заключается в создании глобальных триггеров, в которых мы отлавливаем события создания таблицы или индекса и встраиваем свою логику для настройки базы данных.
CREATE TRIGGER [CustomSettingsMaintenance_OnIndexCreate]ON ALL SERVERAFTER CREATE_INDEXASBEGINSET NOCOUNT ONDECLARE @SchemaName SYSNAME,@TableName SYSNAME,@DatabaseName SYSNAME,@IndexName SYSNAME;SELECT @TableName = EVENTDATA().value('(/EVENT_INSTANCE/TargetObjectName)[1]','SYSNAME')SELECT @SchemaName = EVENTDATA().value('(/EVENT_INSTANCE/SchemaName)[1]','SYSNAME')SELECT @IndexName = EVENTDATA().value('(/EVENT_INSTANCE/ObjectName)[1]','SYSNAME')SELECT @DatabaseName = EVENTDATA().value('(/EVENT_INSTANCE/DatabaseName)[1]','SYSNAME');-- Здесь выполняем необходимые действия.-- Например, возможные варианты:-- 1. Пересоздаем индекс с учетом новой файловой группы-- 2. Вызываем ошибку, если реструктуризация на этой таблице-- не должна проходить автоматически. В этом случае-- обновление базы будет доступно после отключения глобальных триггеров,-- зато не будет непредвиденных падений информационной системы.-- 3. Ничего не делаем, если платформенная реструктуризация работает как надо.END
Как пересоздать индекс с учетом новой файловой группы? Например, у нас есть таблица “_InfoRg4683” и индекс “_InfoRg4683_ByDims_NNNNNNNNNNBN” (это из примера с регистром сведений “История адресных объектов”), при этом основная файловая группа в базе это “PRIMARY”. Имея уже такие данные мы можем написать такой скрипт.
Скрипт генерирует команду “CREATE INDEX” для уже существующего индекса, а в ней мы просто подменяем имя файловой группы.
-- Исходные параметрыDECLARE @tableNameForChange SYSNAME = '_InfoRg4683',@indexNameForChange SYSNAME = '_InfoRg4683_ByDims_NNNNNNNNNNBN',@CreateIndexSQL nvarchar(max);-- Запрос генерирует команду создания индексаSELECT @CreateIndexSQL =(' CREATE ' +CASE WHEN I.is_unique = 1 THEN ' UNIQUE ' ELSE '' END +I.type_desc COLLATE DATABASE_DEFAULT +' INDEX ' +I.name + ' ON ' +Schema_name(T.Schema_id)+'.'+T.name + ' ( ' +KeyColumns + ' ) ' +ISNULL(' INCLUDE ('+IncludedColumns+' ) ','') +ISNULL(' WHERE '+I.Filter_definition,'') + ' WITH ( ' +CASE WHEN I.is_padded = 1 THEN ' PAD_INDEX = ON ' ELSE ' PAD_INDEX = OFF ' END + ',' +'FILLFACTOR = '+CONVERT(CHAR(5),CASE WHEN I.Fill_factor = 0 THEN 100 ELSE I.Fill_factor END) + ',' +-- default value'SORT_IN_TEMPDB = OFF ' + ',' +CASE WHEN I.ignore_dup_key = 1 THEN ' IGNORE_DUP_KEY = ON ' ELSE ' IGNORE_DUP_KEY = OFF ' END + ',' +CASE WHEN ST.no_recompute = 0 THEN ' STATISTICS_NORECOMPUTE = OFF ' ELSE ' STATISTICS_NORECOMPUTE = ON ' END + ',' +-- default value' DROP_EXISTING = ON ' + ',' +-- default value' ONLINE = OFF ' + ',' +CASE WHEN I.allow_row_locks = 1 THEN ' ALLOW_ROW_LOCKS = ON ' ELSE ' ALLOW_ROW_LOCKS = OFF ' END + ',' +CASE WHEN I.allow_page_locks = 1 THEN ' ALLOW_PAGE_LOCKS = ON ' ELSE ' ALLOW_PAGE_LOCKS = OFF ' END + ' ) ON [' +DS.name + '] ')FROM sys.indexes IJOIN sys.tables T ON T.Object_id = I.Object_idJOIN sys.sysindexes SI ON I.Object_id = SI.id AND I.index_id = SI.indidJOIN (SELECT * FROM (SELECT IC2.object_id , IC2.index_id ,STUFF((SELECT ' , ' + C.name + CASE WHEN MAX(CONVERT(INT,IC1.is_descending_key)) = 1 THEN ' DESC ' ELSE ' ASC ' ENDFROM sys.index_columns IC1JOIN Sys.columns CON C.object_id = IC1.object_idAND C.column_id = IC1.column_idAND IC1.is_included_column = 0WHERE IC1.object_id = IC2.object_idAND IC1.index_id = IC2.index_idGROUP BY IC1.object_id,C.name,index_idORDER BY MAX(IC1.key_ordinal)FOR XML PATH('')), 1, 2, '') KeyColumnsFROM sys.index_columns IC2WHERE IC2.Object_id = object_id(@tableNameForChange)GROUP BY IC2.object_id ,IC2.index_id) tmp3 )tmp4ON I.object_id = tmp4.object_id AND I.Index_id = tmp4.index_idJOIN sys.stats ST ON ST.object_id = I.object_id AND ST.stats_id = I.index_idJOIN sys.data_spaces DS ON I.data_space_id=DS.data_space_idJOIN sys.filegroups FG ON I.data_space_id=FG.data_space_idLEFT JOIN (SELECT * FROM (SELECT IC2.object_id , IC2.index_id ,STUFF((SELECT ' , ' + C.nameFROM sys.index_columns IC1JOIN Sys.columns CON C.object_id = IC1.object_idAND C.column_id = IC1.column_idAND IC1.is_included_column = 1WHERE IC1.object_id = IC2.object_idAND IC1.index_id = IC2.index_idGROUP BY IC1.object_id,C.name,index_idFOR XML PATH('')), 1, 2, '') IncludedColumnsFROM sys.index_columns IC2WHERE IC2.Object_id = object_id(@tableNameForChange)GROUP BY IC2.object_id ,IC2.index_id) tmp1WHERE IncludedColumns IS NOT NULL ) tmp2ON tmp2.object_id = I.object_id AND tmp2.index_id = I.index_idWHERE I.is_primary_key = 0 AND I.is_unique_constraint = 0AND I.Object_id = object_id(@tableNameForChange)AND I.name = @indexNameForChange-- Заменяем исходную файловую группу на необходимуюSET @CreateIndexSQL = REPLACE(@CreateIndexSQL, 'ON [PRIMARY]', 'ON [FILEGROUP_3]');-- Пересоздаем индексexec sp_executesql @CreateIndexSQL;
Параметр “DROP_EXISTING = ON” позволяет избежать ошибки, что такой индекс уже существует. В этом случае СУБД удалит старый индекс и создаст новый.
Также есть несколько нюансов при пересоздании индексов с новыми файловыми группами:
- При пересоздании кластерного индекса с новой файловой группой, все остальные индексы таблицы будут также созданы с этой файловой группой.
- Для большей универсальности имя новой и старой файловой группы можно получать динамически, вместо явного указания в скрипте.
- Пользователь СУБД, от имени которого выполняется реструктуризация, должен иметь необходимые привилегии для выполнения запросов.
А что на счет остановки реструктуризации, если она начинается на таблице, где этого происходить не должно?
В триггере проверяем имя таблицы и/или индекса и если он попадает под запрет, то выполняем:
CREATE TRIGGER [StopUpdateInfobase_OnIndexCreate]ON ALL SERVERAFTER CREATE_INDEXASBEGINSET NOCOUNT ONDECLARE @SchemaName SYSNAME,@TableName SYSNAME,@DatabaseName SYSNAME,@IndexName SYSNAME;SELECT @TableName = EVENTDATA().value('(/EVENT_INSTANCE/TargetObjectName)[1]','SYSNAME')SELECT @SchemaName = EVENTDATA().value('(/EVENT_INSTANCE/SchemaName)[1]','SYSNAME')SELECT @IndexName = EVENTDATA().value('(/EVENT_INSTANCE/ObjectName)[1]','SYSNAME')SELECT @DatabaseName = EVENTDATA().value('(/EVENT_INSTANCE/DatabaseName)[1]','SYSNAME');IF(@TableName LIKE '_InfoRg4683' OR @TableName LIKE '_InfoRg4683NG')BEGINDECLARE @msg nvarchar(max) = 'Реструктуризация таблицы ' + @TableName + ' запрещена!';RAISERROR (@msg, 10, 1);THROW 51000, 'Обнаружен запрет реструктуризации таблицы базы данных!', 1;ENDEND
При попытке запуска обновления информационной базы получим ошибку.
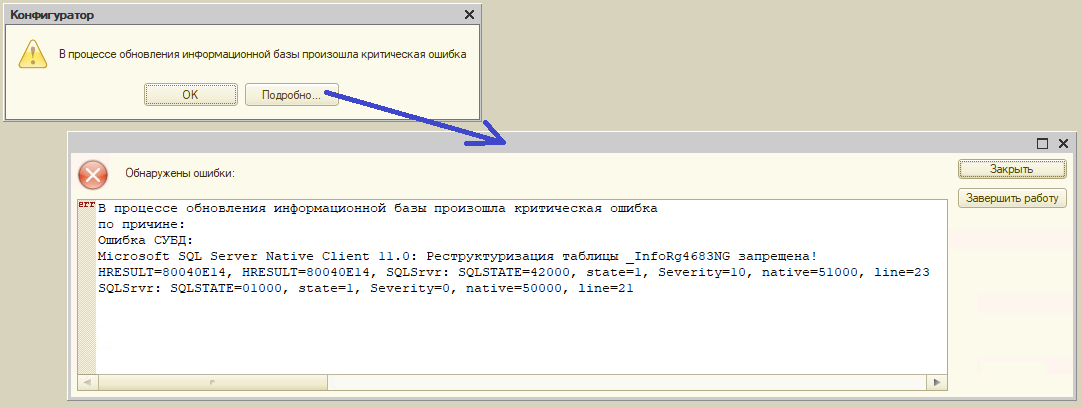
Можно пойти дальше и не ограничиваться отдельными скриптами, а вынести все подобные ограничения и настройки в отдельный инструмент, как это было сделано здесь.
Послесловие
На первый, второй и третий взгляд все это может показаться настоящим монстром, особенно для сопровождения. Что ж, так оно и есть! Остается надеяться, что наступят светлые времена, когда платформа 1С позволит использовать возможности СУБД без таких костылей. А пока на этом все!
Удачи в бою!