Мониторинг SQL Server с помощью Extended Events (и не только). Как держать руку на пульсе?
#SQL Server
#мониторинг
#Extended Events
#логи
#производительность
#оптимизация
Немного истории
Как показывает практика, во многих компаниях малого и среднего бизнеса (а иногда и крупного) можно столкнуться с отсутствием должного обслуживания серверов баз данных. В самом крайнем случае это выражается в наличии неэффективной стратегии бэкапирования или, о ужас, ее полном отсутствии! Представьте, что произойдет, если после аварии не удастся восстановить базу со всеми данными о деятельности компании?
Приходилось ли Вам сталкиваться с системными администраторами, которые в случае проблем производительности и стабильности баз 1С отвечают:
- Это не наша проблема! Обращайтесь к разработчикам 1С.
- С нашей стороны все в порядке, это 1С так работает.
- Какая еще 1С? Мне нужно настроить AD, а также провести миграцию некоторых серверов в облака.
- (просто молча убегают в закат) и др. странные ситуации.
Знакомо? С одной стороны админов понять можно, ведь для исправления подобных проблем нужны время и знания (иногда специфические), за которые работодатель и платить то не всегда готов. С другой стороны, если не администратор должен за этим следить, то кто? Админа БД не везде можно найти и нанять.
Разработчики 1С также не всегда имеют необходимые компетенции и получается замкнутый круг. Разработчики показывают пальцем на админа, а админ на “этих” 1Сников. Причем у разработчиков даже прав доступа может не быть для решения проблем. В итоге бизнес заказывает внешний аудит производительности :)
Как тут быть? Все просто (ну, почти) - нужно кооперироваться. Можно настроить мониторинг на SQL Server силами админа, а результаты показывать разработчикам 1С и обсуждать что нужно для решения проблем. Согласитесь, сесть раз в неделю или раз в месяц и разобрать проблемы - займет намного меньше сил и нервов, если продолжать спихивать друг на друга ответственность и конфликтовать. * Конечно, это работает только при адекватности всех сторон.
Сегодня в статье мы рассмотрим простые способы настройки мониторинга SQL Server с помощью Extended Events и с некоторыми другими способами, а также продемонстрируем как собранные данные интерпретировать и что показать 1Сникам.
Внимание! Статья не является полным руководством.Здесь Вы найдете общую информацию и примеры,а также ссылки на полезные материалы по связанным темам.
Extended Events vs. SQL Profiler (SQL Trace)
Прежде чем перейти непосредственно к примерам настроек сбора данных, нужно пояснить почему все же предлагается использовать Extended Events вместо SQL Profiler. Несомненно, SQL Profiler остается одним из самых используемых инструментов для диагностики работы SQL Server, несмотря на то, что считается устаревшим. Не зря Microsoft предупреждает, что он может быть удален в будущих версиях СУБД, ведь ему на смену давно пришел более продвинутый инструмент - Extended Events.
SQL Profiler является графической надстройкой для SQL Trace, с помощью которой он собирает данные, а после выводит их в графический интерфейс приложения. Как и SQL Profiler, SQL Trace считается устаревшим инструментом и может быть удален в будущем. Так почему же расширенные события лучше старых добрых трасс?
- SQL Trace находится в режиме поддержки и не дополняется новым функционалом. Также он изначально содержал меньше доступных событий для анализа. К тому же, Extended Events содержит больше информации о событиях. Сравните возможности SQL Trace и Extended Events для различных редакций SQL Server по количеству доступных событий.
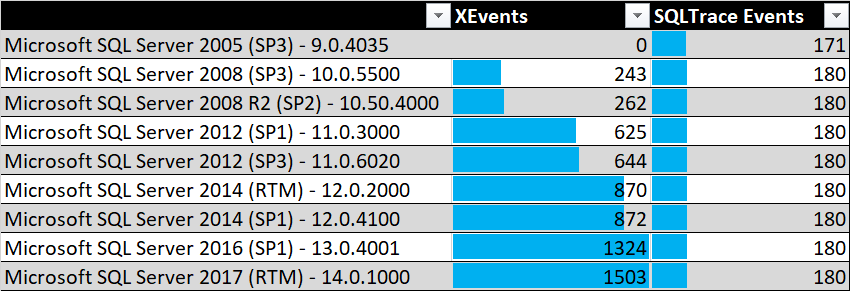
- Значительно меньшее влияние на производительность при включенном сборе данных, причем имеются расширенные настройки, с помощью которых на это можно влиять.
- Настройки сбора данных (события, фильтры и др.) можно менять на активных сессиях, прямо во время сбора данных.
- Доступен хэш запросов, чтобы идентифицировать одинаковые тексты запросов.
- Можно настроить различные способы хранения логов, причем одновременно в нескольких вариантах.
- Встроенные инструменты в SQL Server Managment Studio и инструкции TSQL для работы с ними.
- Поддержка PowerShell :)
- И еще многое другое.
Все еще используйте SQL Profiler / SQL Trace? Я тоже! Но, SQL Profiler только для тестовых баз, где нужно быстро посмотреть, что там за запрос. Если же нужно выполнять работы на рабочем окружении или настраивать мониторинг, то только Extended Events!
Собираем данные
И так, Вы собираетесь использовать расширенные события, но куда смотреть? В SQL Server Managment Studio в разделе “Управление ➡️ Расширенные события ➡️ Сеансы” Вы можете найти список всех сеансов расширенных событий.
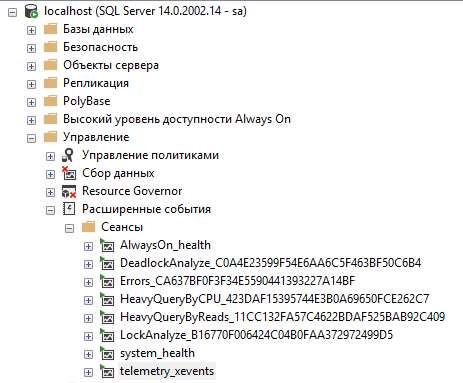
Здесь же можно добавить новый сеанс расширенных событий с помощью мастера, так и с помощью полной настройки вручную с нуля. Также можно управлять состоянием каждого сеанса (остановить или запустить), удалить его или сформировать скрипт T-SQL на основе существующего объекта.
Рассматривать процесс создания сеанса с помощью графического интерфейса мы не будем. Вместо этого создадим основные сеансы расширенных событий с помощью T-SQL.
Помните! Все что описано ниже лишь примеры и их нужно адаптировать под конкретную ситуацию: устанавливать фильтры по базе, настраивать хранение сеансов, добавлять другие необходимые события или удалять лишние, изменять состав собираемых полей и так далее. Главное начать, а там уже все будет проще!
Тяжелые запросы по CPU
Обычно всех интересуют долгие по времени выполнения запросы, или запросы отбирающие больше всего ресурсов CPU. Это не одно и то же, ведь на сервере может быть включен параллелизм, тогда затраченное процессорное время не будет равно времени выполнения запроса даже приблизительно. Для отслеживания событий по CPU достаточно использовать два события: RPC:Completed и SQL:BatchCompleted. Первое событие возникает при вызове процедур, которые обычно делает платформа 1С через обращение к sp_executesql. Практически во всех остальных случаях это второе событие выполнения пакета запросов.
Также стоит учитывать, чтоб сбор абсолютно всех запросов особо смысла не имеет и их нужно отфильтровать от “шума”. Для этого можно установить фильтр по полю времени выполнения события (поле “duration”). Значения там хранятся в микросекундах. Обычно я собираю запросы, которые выполняются более 5 секунд (то есть более 5000000 микросекунд).
Чтобы создать сеанс сбора таких запросов воспользуется следующим скриптом. Оригинальный скрипт находится здесь.
-- Анализ тяжелых запросов по CPUCREATE EVENT SESSION [HeavyQueryByCPU] ON SERVER-- Класс событий RPC:Completed указывает, что удаленный вызов процедуры завершен.-- https://docs.microsoft.com/ru-ru/sql/relational-databases/event-classes/rpc-completed-event-class?view=sql-server-2017ADD EVENT sqlserver.rpc_completed(ACTION(sqlserver.client_app_name,sqlserver.client_hostname,sqlserver.client_pid,sqlserver.database_id,sqlserver.nt_username,sqlserver.server_principal_name,sqlserver.session_id,sqlserver.sql_text,sqlserver.transaction_id,sqlserver.username)WHERE ([duration]>(5000000))),-- Класс событий SQL:BatchCompleted указывает на завершение выполнения пакета языка Transact-SQL.-- https://docs.microsoft.com/ru-ru/sql/relational-databases/event-classes/sql-batchcompleted-event-class?view=sql-server-2017ADD EVENT sqlserver.sql_batch_completed(ACTION (sqlserver.client_app_name,sqlserver.client_hostname,sqlserver.client_pid,sqlserver.database_id,sqlserver.nt_username,sqlserver.server_principal_name,sqlserver.session_id,sqlserver.sql_text,sqlserver.transaction_id,sqlserver.username)WHERE ([duration]>(5000000)))ADD TARGET package0.event_file(SET-- Путь к файлу хранения логов. Если не указан, то используется путь к каталогу логов SQL Serverfilename=N'HeavyQueryByCPU.xel',-- Максимальный размер файла в мегабайтахmax_file_size=(1024),-- Максимальное количество файлов, после чего начнется перезапись логов в более старых файлах.max_rollover_files=(5))WITH (MAX_MEMORY=4096 KB,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,MAX_DISPATCH_LATENCY=15 SECONDS,MAX_EVENT_SIZE=0 KB,MEMORY_PARTITION_MODE=NONE,TRACK_CAUSALITY=OFF,STARTUP_STATE=OFF)
При использовании не забудьте указать путь, где будут хранится файлы с результатами логирования.
Таким образом, мы соберем все запросы, которые выполняются более 5 секунд, а дальше уже сможем агрегировать их и получить свой TOP по нагрузке.
Тяжелые запросы по объему данных
На втором месте для поиска тяжелых запросов используется объем логических чтений. Именно логических. То есть тех, которые были выполнены из оперативной памяти. Это важно, т.к. SQL Server кэширует страницы, полученные с диска в буферный кэш, то есть в оперативную память. Именно поэтому SQL Server такой прожорливый в части использования RAM (особенно если его не ограничить в настройках инстанса), но зато позволяет значительно повысить производительность. Тут главное соблюдать баланс.
Сбор тяжелых запросов по логическим чтениям позволит определить те запросы, которые чаще всего используют буферный кэш, тем самым “вымывая” из него данные для других запросов. Что это значит? Допустим, на сервере 32 ГБ оперативной памяти. Бухгалтер запустил отчет, запрос которого благодаря усилиями разработчика, считал 25 ГБ данных. Тем самым весь буфферный кэш SQL Server теперь используется этим отчетом, а остальные запросы будут вынуждены обращаться к диску и заново получать страницы, помещать их в кэш. Фактически, пользователи столкнуться с замедлением работы информационной системы. Описание, конечно, общее, но смысл должен быть понятен.
Собирать будем те же события, что и для CPU: RPC:Completed и SQL:BatchCompleted. Для избавления от избыточного логирования событий в этом случае необходимо поставить фильтр на поле с размером прочитанных данных (то есть “logical reads”). На практике все зависит от конкретной системы и размера базы. Обычно использую значение фильтра от 10000 до 50000 прочитанных страниц (то есть от ~80 МБ до ~400 МБ, т.к. 1 страница = 8 КБ).
Для создания сеанса сбора тяжелых запросов по считываемому объему данных из кэша используем скрипт.Оригинальный скрипт здесь.
-- Анализ тяжелых запросов по чтению данныхCREATE EVENT SESSION [HeavyQueryByReads] ON SERVER-- Класс событий RPC:Completed указывает, что удаленный вызов процедуры завершен.-- https://docs.microsoft.com/ru-ru/sql/relational-databases/event-classes/rpc-completed-event-class?view=sql-server-2017ADD EVENT sqlserver.rpc_completed(ACTION (sqlserver.client_app_name,sqlserver.client_hostname,sqlserver.client_pid,sqlserver.database_id,sqlserver.nt_username,sqlserver.query_hash,sqlserver.query_plan_hash,sqlserver.server_principal_name,sqlserver.session_id,sqlserver.sql_text,sqlserver.transaction_id,sqlserver.username)WHERE ([logical_reads]>(50000))),-- Класс событий SQL:BatchCompleted указывает на завершение выполнения пакета языка Transact-SQL .-- https://docs.microsoft.com/ru-ru/sql/relational-databases/event-classes/sql-batchcompleted-event-class?view=sql-server-2017ADD EVENT sqlserver.sql_batch_completed(ACTION (sqlserver.client_app_name,sqlserver.client_hostname,sqlserver.client_pid,sqlserver.database_id,sqlserver.nt_username,sqlserver.query_hash,sqlserver.query_plan_hash,sqlserver.server_principal_name,sqlserver.session_id,sqlserver.sql_text,sqlserver.transaction_id,sqlserver.username)WHERE ([logical_reads]>(50000)))ADD TARGET package0.event_file(SET-- Путь к файлу хранения логов. Если не указан, то используется путь к каталогу логов SQL Serverfilename=N'HeavyQueryByReads.xel',-- Максимальный размер файла в мегабайтахmax_file_size=(1024),-- Максимальное количество файлов, после чего начнется перезапись логов в более старых файлах.max_rollover_files=(5))WITH (MAX_MEMORY=4096 KB,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,MAX_DISPATCH_LATENCY=15 SECONDS,MAX_EVENT_SIZE=0 KB,MEMORY_PARTITION_MODE=NONE,TRACK_CAUSALITY=OFF,STARTUP_STATE=OFF)
При необходимости измените настройки под себя.
В итоге будем иметь статистику какие запросы у нас “прожорливые” по чтению.
Анализ блокировок и взаимоблокировок
В платформе 1С реализован собственный менеджер блокировок. Всем известные управляемые блокировки должны были повысить производительность, что в принципе и сделали. Но, конечно же, отказа от использования блокировок на уровне СУБД не произошло, т.к. поддержание целостности данных никто не отменял. Поэтому мониторинг блокировок и взаимоблокировок на уровне СУБД является также актуальным.
Для получения информации о возникших таймаутах на блокировках, ожиданиях на блокировках и взаимоблокировках можно воспользоваться следующими способоми.
Регулярный сбор информации об ожиданиях, таймаутах и взаимоблокировках
Для минимального влияния на работу базы данных и сервера СУБД рекомендую собирать информацию об ожиданиях на блокировках с помощью механизма отчетов по заблокированным процессам. Он включается в свойствах сервера и выполняет сбор статистики с заданной периодичностью (обычно 5 секунд достаточно). При этом сбора информации обо всех установленных блокировках не производится, что снижает нагрузку на сервер. Мы получим только необходимую информацию о том, какой процесс кого ждал, какие запросы выполнялись и так далее.
Дополняем сессию сбора событиями отчета по взаимоблокировкам, чтобы в этот же отчет получить информацию о взаимоблокировках, их XML-граф и связаную информацию.
Информацию о событиях читайте в официальной документации: Blocked Process Report и Deadlock XML Report.
-- Анализ блокировок и взаимоблокировок с помощью отчетов-- Предварительно нужно включить события отчетов заблокированных процессов-- https://docs.microsoft.com/ru-ru/sql/relational-databases/event-classes/blocked-process-report-event-class?view=sql-server-ver15EXEC sp_configure 'show advanced options', 1 ;GORECONFIGURE ;GOEXEC sp_configure 'blocked process threshold', '5';RECONFIGUREGO-- Далее создаем сессию сбор данных событий заблокированных процессов и взаимоблокировокCREATE EVENT SESSION [BlocksAndDeadlocksAnalyse] ON SERVERADD EVENT sqlserver.blocked_process_report(ACTION(sqlserver.client_app_name,sqlserver.client_hostname,sqlserver.database_name)) ,ADD EVENT sqlserver.xml_deadlock_report (ACTION(sqlserver.client_app_name,sqlserver.client_hostname,sqlserver.database_name))ADD TARGET package0.asynchronous_file_target(SET filename = N'LockAndDeadlockAnalyzeReports.xel',metadatafile = N'LockAndDeadlockAnalyzeReports.xem',max_file_size=(5000),max_rollover_files=10)WITH (MAX_DISPATCH_LATENCY = 5SECONDS)GO/*Результат сессии содержит подробную информацию о событиях блокировок и взаимоблокировок:- Какая сессия какие блокировала- Сколько происходило ожидание на блокироваке- Какие запросы участвовали с обоих сторон- И другая информация*/ALTER EVENT SESSION [BlocksAndDeadlocksAnalyse] ON SERVERWITH (STARTUP_STATE=ON)GO
В целом, данных подход позволяет взять под контроль абсолютное большинство проблем с ожиданиями на блокировках, таймаутами или взаимоблокировками. При этом минимально влияя на работу сервера СУБД и базы данных в частности.
Детальный анализ работы блокировочного механизма
Второй способ с более детальным анализом можно использовать следующий, но он может сильно повлиять на работу сервера баз данных. Используйте в тех случаях, когда ранее описанный метод не позволяет проанализировать причины происходящих проблем.
Создаем сессию сбора информации обо всех возникших блокировках в системе, их отмене и таймаутах. При этом информацию записываем в файл, но с ограничением максимального размера в 1 ГБ. Максимальное количество файлов установим в 3. Выбранные события для сессии это: Lock:Acquired (возникновение блокировки), Lock:Cancel (отмена блокировки), Lock:Timeout (таймаут на блокировке). Еще дополнительно можно собирать данные по событию Lock:Escalation (эскалация блокировки), но это по необходимости.
Сеанс собирает данные обо всех возникающих блокировках, отмененных блокировках и таймаутах. На нагруженных системах он может очень быстро увеличиваться в размерах, что потребует дискового пространства. Обычно сбор этих сведений выполняется в период пиковых нагрузок или в моменты времени, когда проблема с блокировками проявляется.
-- Анализ блокировокCREATE EVENT SESSION [LockAnalyze] ON SERVER-- Класс событий Lock:Acquired указывает, что была получена блокировка для ресурса-- https://docs.microsoft.com/ru-ru/sql/relational-databases/event-classes/lock-acquired-event-class?view=sql-server-2017ADD EVENT sqlserver.lock_acquired(ACTION (sqlserver.client_app_name,sqlserver.client_hostname,sqlserver.client_pid,sqlserver.database_id,sqlserver.nt_username,sqlserver.server_principal_name,sqlserver.session_id,sqlserver.sql_text,sqlserver.transaction_id,sqlserver.username)),-- Класс событий Lock:Cancel сигнализирует, что получение блокировки на ресурс было отменено-- https://docs.microsoft.com/ru-ru/sql/relational-databases/event-classes/lock-cancel-event-class?view=sql-server-2017ADD EVENT sqlserver.lock_cancel(ACTION (sqlserver.client_app_name,sqlserver.client_hostname,sqlserver.client_pid,sqlserver.database_id,sqlserver.nt_username,sqlserver.server_principal_name,sqlserver.session_id,sqlserver.sql_text,sqlserver.transaction_id,sqlserver.username)),-- Класс событий Lock:Timeout указывает на то, что запрос на захват некоторого ресурса превысил время ожидания-- https://docs.microsoft.com/ru-ru/sql/relational-databases/event-classes/lock-timeout-event-class?view=sql-server-2017ADD EVENT sqlserver.lock_timeout(WHERE ([duration]>(1) AND [resource_0]<>(0)))ADD TARGET package0.event_file(SET-- Путь к файлу хранения логов. Если не указан, то используется путь к каталогу логов SQL Serverfilename=N'LockAnalyze.xel',-- Максимальный размер файла в мегабайтахmax_file_size=(1024),-- Максимальное количество файлов, после чего начнется перезапись логов в более старых файлах.max_rollover_files=(5))WITH (MAX_MEMORY=4096 KB,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,MAX_DISPATCH_LATENCY=15 SECONDS,MAX_EVENT_SIZE=0 KB,MEMORY_PARTITION_MODE=NONE,TRACK_CAUSALITY=OFF,STARTUP_STATE=OFF)
Может понадобиться изменить настройки куда будет сохраняться файл с логами, а также ограничения на макс. размер файла и их количество.
После этого, для анализа данных собранных логов лучше перенести их в отдельную базу данных. Последующий анализ заключается в поиске запроса, который блокировал выполнение текущей инструкции и привел к таймауту.
Также есть другой способ для оперативного анализа кто и что блокирует. Для этого создадим сессию с доп. событием SQL:LockReleased, которое показывает снятие блокировки с ресурса. Вот так будут выглядеть скрипты оперативного анализа блокировок.
IF EXISTS(SELECT * FROM sys.server_event_sessions WHERE name='LockAnalyze_Operational')DROP EVENT SESSION LockAnalyze_Operational ON SERVERGODECLARE @dbid int-- Для фильтра по базе данныхSELECT @dbid = db_id('<ИмяБазыДанных>')IF @dbid IS NULLBEGINRETURNEND-- Создаем сессию для анализа блокировокDECLARE @sql nvarchar(1024)SET @sql = 'CREATE EVENT SESSION LockAnalyze_Operational ON SERVERADD EVENT sqlserver.lock_acquired(action( sqlserver.sql_text, sqlserver.database_id, sqlserver.tsql_stack,sqlserver.plan_handle, sqlserver.session_id)WHERE ( database_id=' + cast(@dbid as nvarchar) + ' AND resource_0!=0)),ADD EVENT sqlserver.lock_released(WHERE ( database_id=' + cast(@dbid as nvarchar) + ' AND resource_0!=0 ))ADD TARGET package0.pair_matching( SET begin_event=''sqlserver.lock_acquired'',begin_matching_columns=''database_id, resource_0, resource_1, resource_2, transaction_id, mode'',end_event=''sqlserver.lock_released'',end_matching_columns=''database_id, resource_0, resource_1, resource_2, transaction_id, mode'',respond_to_memory_pressure=1)WITH (max_dispatch_latency = 1 seconds)'EXEC (@sql)ALTER EVENT SESSION LockAnalyze_Operational ON SERVERSTATE = START
Ждем выполнения проблемной нагрузки.
-- Сохраняем данные сессии во временную таблицу для последующего анализаSELECTobjlocks.value('(action[@name="session_id"]/value)[1]', 'int')AS session_id,objlocks.value('(data[@name="database_id"]/value)[1]', 'int')AS database_id,objlocks.value('(data[@name="resource_type"]/text)[1]', 'nvarchar(50)' )AS resource_type,objlocks.value('(data[@name="resource_0"]/value)[1]', 'bigint')AS resource_0,objlocks.value('(data[@name="resource_1"]/value)[1]', 'bigint')AS resource_1,objlocks.value('(data[@name="resource_2"]/value)[1]', 'bigint')AS resource_2,objlocks.value('(data[@name="mode"]/text)[1]', 'nvarchar(50)')AS mode,objlocks.value('(action[@name="sql_text"]/value)[1]', 'varchar(MAX)')AS sql_text,CAST(objlocks.value('(action[@name="plan_handle"]/value)[1]', 'varchar(MAX)') AS xml)AS plan_handle,CAST(objlocks.value('(action[@name="tsql_stack"]/value)[1]', 'varchar(MAX)') AS xml)AS tsql_stackINTO #unmatched_locksFROM (SELECT CAST(xest.target_data as xml)lockinfoFROM sys.dm_xe_session_targets xestJOIN sys.dm_xe_sessions xes ON xes.address = xest.event_session_addressWHERE xest.target_name = 'pair_matching' AND xes.name = 'LockAnalyze_Operational') heldlocksCROSS APPLY lockinfo.nodes('//event[@name="lock_acquired"]') AS T(objlocks)-- Получаем результаты анализаSELECTul.session_id [Сессия],ul.[database_id] AS [ID базы данных],ul.resource_type AS [Тип ресурса],ul.resource_0 AS [Ресурс0],ul.resource_1 AS [Ресурс1],ul.resource_2 AS [Ресурс2],ul.mode AS [Режим блокировки],ul.sql_text AS [Текст запроса],ul.plan_handle AS [Идентификатор плана запроса]FROM #unmatched_locks ulINNER JOIN sys.dm_tran_locks tl ON ul.database_id = tl.resource_database_id AND ul.resource_type = tl.resource_typeWHERE resource_0 IS NOT NULLAND session_id IN(SELECT blocking_session_id FROM sys.dm_exec_requests WHERE blocking_session_id != 0)AND tl.request_status='wait'AND REPLACE(ul.mode, 'LCK_M_', '' ) = tl.request_mode-- Удаляем временную таблицу и сессию расширенных событийDROP TABLE #unmatched_locksDROP EVENT SESSION FindBlockers ON SERVER
Так мы получим информацию о причинах таймаутов анализируя меньший объем логов, чем в первом примере.
Для сбора и последующего анализа причин взаимоблокировок можно использовать сессию, в которой собираются данные событий Lock:Deadlock, Lock:Deadlock Chain и Deadlock XML Report для построения графического отчета.
-- Анализ взаимоблокировокCREATE EVENT SESSION [DeadlockAnalyze] ON SERVER-- Класс событий Lock:Deadlock предназначен для отслеживания возникновения взаимоблокировок и объектов, которые в них участвуют.-- https://docs.microsoft.com/ru-ru/sql/relational-databases/event-classes/lock-deadlock-event-class?view=sql-server-2017ADD EVENT sqlserver.lock_deadlock(ACTION(sqlserver.client_app_name,sqlserver.client_hostname,sqlserver.client_pid,sqlserver.database_id,sqlserver.nt_username,sqlserver.server_principal_name,sqlserver.session_id,sqlserver.sql_text,sqlserver.transaction_id,sqlserver.username)),-- Класс событий Lock:Deadlock Chain используется для регистрации условий возникновения взаимоблокировок.-- https://docs.microsoft.com/ru-ru/sql/relational-databases/event-classes/lock-deadlock-chain-event-class?view=sql-server-2017ADD EVENT sqlserver.lock_deadlock_chain(ACTION(sqlserver.client_app_name,sqlserver.client_hostname,sqlserver.client_pid,sqlserver.database_id,sqlserver.nt_username,sqlserver.server_principal_name,sqlserver.session_id,sqlserver.sql_text,sqlserver.transaction_id,sqlserver.username)),-- Создает отчет о событии взаимоблокировки в формате XMLADD EVENT sqlserver.xml_deadlock_report(ACTION(sqlserver.client_app_name,sqlserver.client_hostname,sqlserver.client_pid,sqlserver.database_id,sqlserver.nt_username,sqlserver.server_principal_name,sqlserver.session_id,sqlserver.sql_text,sqlserver.transaction_id,sqlserver.username))ADD TARGET package0.event_file(SET-- Путь к файлу хранения логов. Если не указан, то используется путь к каталогу логов SQL Serverfilename=N'DeadlockAnalyze.xel',-- Максимальный размер файла в мегабайтахmax_file_size=(10),-- Максимальное количество файлов, после чего начнется перезапись логов в более старых файлах.max_rollover_files=(5))WITH (MAX_MEMORY=4096 KB,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,MAX_DISPATCH_LATENCY=15 SECONDS,MAX_EVENT_SIZE=0 KB,MEMORY_PARTITION_MODE=NONE,TRACK_CAUSALITY=OFF,STARTUP_STATE=OFF)
Как обработать отчет по взаимоблокировкам
В обоих вариантах сбора информации о блакировках используется сбор XML-отчета о взаимоблокировке. Обработать его можно одинаково в обоих случаях.
Обычно взаимоблокировки достаточно редкое явление, но мониторить их нужно в любом случае. Чтобы получить файл графа взаимоблокировки (*.xdl) из XML расширенного события необходимо скопировать вот этот значение в отдельный файл с расширением “xdl”.
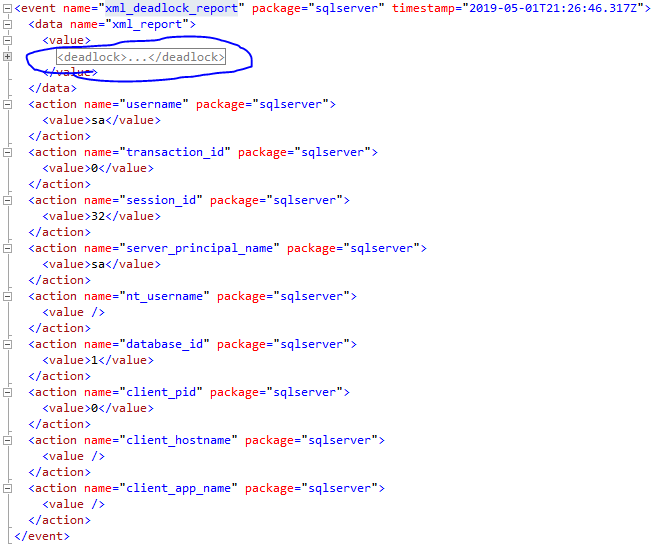
После этого файл графа можно открывать в SQL Server Managment Studio.

Остальные события помогут найти конкретные запросы и причины их появления.
Желаю Вам отсутствия взаимоблокировок!
Теперь Вы знаете как собрать информацию о запросах, приводящих к появлению таймаутов на блокировках и взаимоблокировкам.
Ошибки, ошибки, ошибки
Было бы не плохо также отслеживать любые ошибки, происходящие на уровне СУБД. Для этого воспользуемся скриптом для сбора всех ошибок с помощью события “SQL:ErrorReported”.
-- Анализ ошибокCREATE EVENT SESSION [Errors] ON SERVERADD EVENT sqlserver.error_reported(ACTION (sqlserver.client_app_name,sqlserver.client_hostname,sqlserver.client_pid,sqlserver.database_id,sqlserver.is_system,sqlserver.nt_username,sqlserver.server_principal_name,sqlserver.session_id,sqlserver.sql_text,sqlserver.transaction_id,sqlserver.transaction_sequence,sqlserver.username)WHERE ([severity]>(10)))ADD TARGET package0.event_file(SET-- Путь к файлу хранения логов. Если не указан, то используется путь к каталогу логов SQL Serverfilename=N'Errors.xel',-- Максимальный размер файла в мегабайтахmax_file_size=(10),-- Максимальное количество файлов, после чего начнется перезапись логов в более старых файлах.max_rollover_files=(5))WITH (MAX_MEMORY=4096 KB,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,MAX_DISPATCH_LATENCY=15 SECONDS,MAX_EVENT_SIZE=0 KB,MEMORY_PARTITION_MODE=NONE,TRACK_CAUSALITY=OFF,STARTUP_STATE=OFF)
Может пригодиться для диагностики не только проблем SQL Server, но и ошибок при выполнении запросов платформой 1С.
Какой у нас план?
Иногда для диагностики проблем необходимо получить план запроса. Собирать планы всех запросов может быть не лучшим решением, т.к. значительно увеличит размер собираемых логов и в особых случаях может повлиять на производительность сервера.
Поэтому лучше использовать такие пути получения плана запроса:
- этот скриптэтот скрипт и посмотрите ее план.
- Найти план выполнения по тексту запроса, если он еще содержится в кэше. Вот пример скрипта.
- Собирать все планы выполнения и повесить сервер с помощью Extended Events. Серьезно! Это только для ознакомления и применяется в редких случаях, особенно на продакшене.
- Есть и другие способы получить план. Вот дополнительная информация по этому поводу.
Теперь, когда у Вас есть план запроса, Вы можете составить свой план работ! :).
Анализируй это
Собрать данные недостаточно, их еще нужно проанализировать! И тут платформа 1С приготовила нам некоторые сюрпризы. Разберем пример сбора и анализа данных собранных тяжелых запросов по CPU, а также анализ событий по таймаутам на блокировках. Все примеры будут очень похожи.
Перенос в отдельную базу данных
И так, сессия Extended Events работает уже несколько рабочих дней и пора перейти к анализу собранных ей данных. Для начала остановим сессию.
Сделать это можно либо через интерфейс.
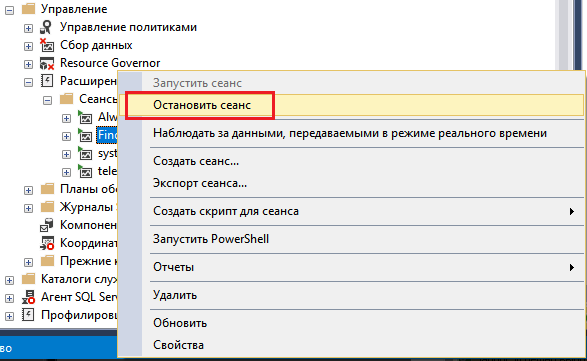
Либо через TSQL.
ALTER EVENT SESSION <ИмяСессии> ON SERVERSTATE = STOP; -- START для запуска
Ничего сложного.
Далее копируем файлы XEL с собранными данными на сервер логов или локальный компьютер, т.к. выполнять анализ данных на рабочем сервере дело рисковое, ведь он может “съесть” значительную часть ресурсов.
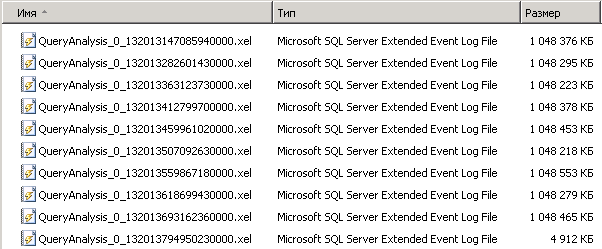
Для удобной работы с логами лучше всего переносить их в базу данных. Конечно, есть возможность работы с ними без сохранения в базу, но это может значительно усложнить процесс обработки и анализа. Например, так мы не сможем повторно работать с данными эффективно, а для данных в базе мы могли бы создать индексы. Кроме того, для платформы 1С собранные данные нужно подвергать постобработке, к которой мы еще вернемся ниже. И так, как же перенести данные расширенных событий в базу.
Исходим из того, что база данных для обработки логов уже создана. Нам лишь нужно эти логи туда загрузить. Для этого запустим SQL Server Managment Studio и перейдем в “Файл ➡️ Открыть ➡️ Объединить файлы расширенных событий….”.
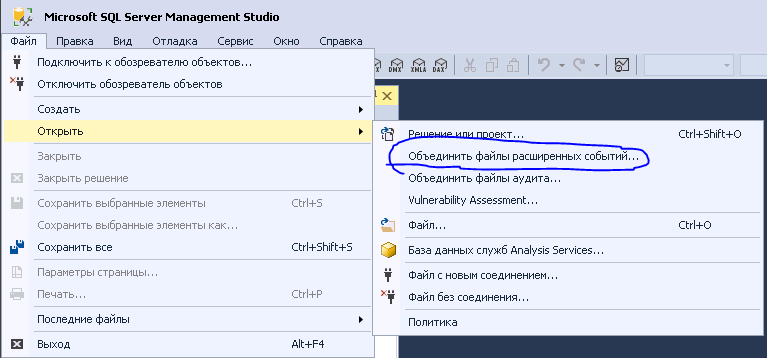
После добавляем в список все файлы, которые хотим обработать. Это намного удобнее, чем загружать каждый отдельный файл логов в базу. Ожидаем некоторое время, пока SSMS не обработает все события. После этого запускаем мастер выгрузки событий в таблицу базы данных.
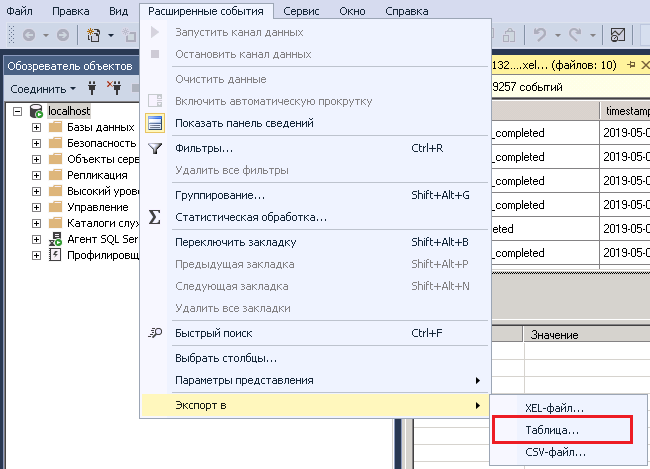
Вводим данные аутентификации, после чего необходимо выбрать базу данных, её схему (по умолчанию “dbo”) и имя таблицы для загрузки данных.
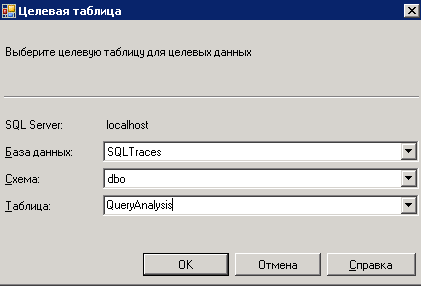
Ожидаем завершение операции экспорта.
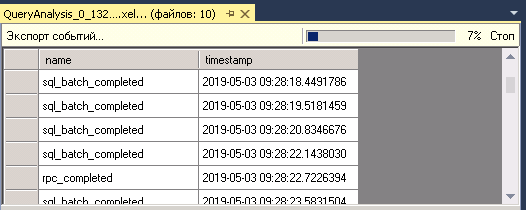
На этом все, SSMS создал таблицу и загрузил туда данные расширенных событий.
Для ознакомительных целей упомянем и способ работы с собранными логами без сохранения в базу данных, но при работе с большим массивом логов он неэффективен.
Чтение файлов XEL через T-SQL выполняется с помощью sys.fn_xe_file_target_read_file. Каждое событие хранится в виде XML и вся задача сводится к разбору этих данных для представления в виде таблицы с отдельными колонками.
selectn.value('(action[@name="database_name"]/value)[1]', 'nvarchar(128)') as database_name,n.value('(@name)[1]', 'varchar(50)') as event_name,n.value('(@package)[1]', 'varchar(50)') AS package_name,n.value('(@timestamp)[1]', 'datetime2') AS [utc_timestamp],n.value('(data[@name="duration"]/value)[1]', 'int') as duration,n.value('(data[@name="cpu_time"]/value)[1]', 'int') as cpu,n.value('(data[@name="physical_reads"]/value)[1]', 'int') as physical_reads,n.value('(data[@name="logical_reads"]/value)[1]', 'int') as logical_reads,n.value('(data[@name="writes"]/value)[1]', 'int') as writes,n.value('(data[@name="row_count"]/value)[1]', 'int') as row_count,n.value('(data[@name="statement"]/value)[1]', 'nvarchar(max)') as statementfrom (select cast(event_data as XML) as event_datafrom sys.fn_xe_file_target_read_file('Q:\SQLTraces\254-sp-sql6\QueryStatistics\QueryAnalysis*.xel', null, null, null)) edcross apply ed.event_data.nodes('event') as q(n)
Если файлов XEL несколько, то есть возможность указать шаблон имени файла через “*”, как это сделано в примере выше.
Этот способ не всегда удобен, т.к. не позволяет делать постобработку, группировку данных, использовать индексы для быстрого поиска и так далее.
И так, мы подготовили логи для дальнейшей обработки, но как оказалось это еще не все. Для быстрой и эффективной работы нам необходимо добавить ключевое поле в таблицу, изменить некоторые колонки и добавить кластерный индекс. Например, вот так:
-- Добавляем уникальное поле ID для каждой записиALTER TABLE [dbo].[QueryAnalysis] ADD ID INT IDENTITY(1,1);-- Изменяем тип колонки "database_name" с "nvarchar(max)" на "nvarchar(150)",-- чтобы его можно было использовать в индексахALTER TABLE [dbo].[QueryAnalysis] ALTER COLUMN [database_name] nvarchar(150) NOT NULL;-- Добавляем кластерный индекс по периоду, имени базы и ключу записиCREATE UNIQUE CLUSTERED INDEX CIX_Timestamp_DatabaseName_ID ON [dbo].[QueryAnalysis]([timestamp (UTC)],[database_name],[ID]);-- Добавляем индекс для быстрого поиска по "ID" + "timestamp (UTC)".-- Для оптимизации включены покрывающие поля, которые содержат тексты запросов,-- но это приводит к увеличению размера базы с логами.CREATE UNIQUE NONCLUSTERED INDEX [UI_ID_Timestamp] ON [dbo].[QueryAnalysis]([ID] ASC,[timestamp (UTC)] ASC)INCLUDE ([batch_text],[sql_text],[database_name],[statement]);-- Если есть возможность, то можно включить сжатие PAGE на уровне таблиц и индексов для базы с логами.-- Так можно значительно сэкономить место.
Эти шаги совсем не обязательные и могут изменяться в зависимости от состава собираемых полей в сессиях. Имеет смысл выполнять эти манипуляции только если данных для анализа много и планируется делать различные запросы для обработки этих записей. Нужен ли индекс, если в логах 10 записей? :)
Отлично, теперь у нас есть таблица с загруженными логами и индекс для эффективной обработки данных.
Эти действия могут отличаться, если состав собираемых полей с помощью Extended Events другой, но общий принцип должен быть понятен. Финальный вариант таблицы с логами выглядит так.
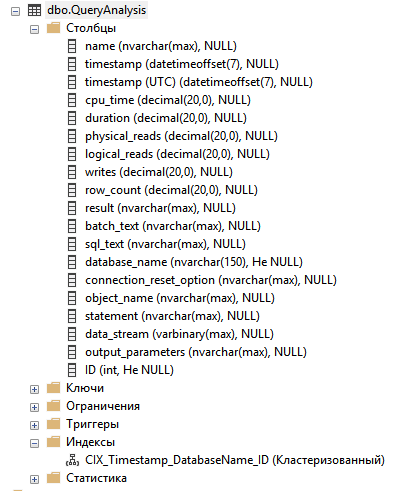
Осталось решить проблему постобработки данных.
Постобработка. Или грабли от 1С
Для SQL-запросов платформы есть одна большая особенность (другие мелкие нюансы можно не рассматривать): имена временных таблиц в запросах могут иметь случайные имена вида “#tt<Тут случайны номер, который присвоит платформа 1С>”. Аналогично обстоят дела и с именами параметров: @P1, @P2 … @PN.
Поэтому было бы не плохо привести их имена к общему виду. Например, к “#ttN” для временных таблиц и @PN для имен параметров.
Есть множество способов сделать постобработку данных. От написания различных программ на C#, Pyton и так далее, до использования самой 1С. Мы же сейчас пойдем другим путем и используем инструмент, который изначально есть на любом Win-сервере. Это PowerShell!
# Строка подключения к базе# Примеры:# - аутентификация средствами NTLM: "Server=<Имя сервера>;Database=<Имя базы>;Integrated Security=TRUE;"# - аутентификация средствами SQL Server: "Data Source=<Имя сервера>;user=<Имя пользователя>;password=<Пароль>;Initial Catalog=<Имя базы>"$connectionString = "<Строка подключения>";# Таблица с логами Extended Events$tableWithLogName = "<Имя таблицы с логами>";# Размер порции для обработки записей$portion = 100;# Таймаут подключения для команд$sqlCmdTimeoutSeconds = 180;try{$sqlConnection = new-object system.data.SqlClient.SQLConnection($connectionString);$sqlConnection.Open();$sqlConnectionForUpdate = new-object system.data.SqlClient.SQLConnection($connectionString);$sqlConnectionForUpdate.Open();# Проверяем наличие колонок в логах$batch_text_exist = $false;$sql_text_exist = $false;$statement_exist = $false;$database_name_exist = $false;$sqlCmd = New-Object System.Data.SqlClient.SqlCommand$sqlCmd.Connection = $sqlConnection$sqlCmd.CommandTimeout = $sqlCmdTimeoutSeconds;$sqlCmd.CommandText = "SELECTcls.column_for_check AS [Name],CASE WHEN cl_info.column_id IS NOT NULL THEN 1 ELSE 0 END AS [exist]FROM (SELECT 'batch_text' column_for_checkUNION ALLSELECT 'sql_text' column_for_checkUNION ALLSELECT 'statement' column_for_checkUNION ALLSELECT 'database_name' column_for_check) clsLEFT JOIN sys.columns cl_infoON cls.column_for_check = cl_info.[name]AND cl_info.[Object_ID] = Object_ID(N'dbo." + $tableWithLogName + "')";$reader = $sqlCmd.ExecuteReader()if($reader.HasRows -eq $true){while ($reader.Read()){if($reader["Name"] -eq "batch_text"){if($reader["exist"] -eq 1){$batch_text_exist = $true;}} elseif($reader["Name"] -eq "sql_text"){if($reader["exist"] -eq 1){$sql_text_exist = $true;}} elseif($reader["Name"] -eq "statement"){if($reader["exist"] -eq 1){$statement_exist = $true;}} elseif($reader["Name"] -eq "database_name"){if($reader["exist"] -eq 1){$database_name_exist = $true;}}}}$reader.Close()if($batch_text_exist -eq $false -and$sql_text_exist -eq $false -and$statement_exist -eq $false){$sqlConnection.Close();$sqlConnectionForUpdate.Close();Write-Host "Таблица ""$tableWithLogName"" не содержит данных для обработки!";return;}$lastRowID = 0;$finish = $false;$fieldForJob = ($(if ($batch_text_exist) {"[batch_text],"} Else {""}) + "" + $(if ($sql_text_exist) {"[sql_text],"} Else {""}) + "" + $(if ($statement_exist) {"[statement],"} Else {""})).Trim();$fieldForJob = $fieldForJob.Substring(0, $fieldForJob.Length - 1);$fieldsForUpdateLogRecord = ($(if ($batch_text_exist) {" [batch_text] = @new_batch_text,"} Else {""}) + "" + $(if ($statement_exist) {" [statement] = @new_statement,"} Else {""}) + "" + $(if ($sql_text_exist) {" [sql_text] = @new_sql_text,"} Else {""})).Trim();$fieldsForUpdateLogRecord = $fieldsForUpdateLogRecord.Substring(0, $fieldsForUpdateLogRecord.Length - 1);Do{$sqlCmd = New-Object System.Data.SqlClient.SqlCommand$sqlCmd.Connection = $sqlConnection$sqlCmd.CommandTimeout = $sqlCmdTimeoutSeconds;$sqlCmd.CommandText = "SELECT TOP (" + $portion + ")-- Ключевые поля[ID]" + $(if ($database_name_exist) {",[database_name]"} Else {""}) + ",[timestamp (UTC)] AS [timestamp]-- Поля для обработки," + $fieldForJob + "FROM [dbo].[" + $tableWithLogName + "]WHERE [ID] > @lastRowIDORDER BY-- Сортировка по ключевым полям[ID],[timestamp (UTC)]";$paramLastRowId = $sqlCmd.Parameters.Add("@lastRowID", $lastRowID);$reader = $sqlCmd.ExecuteReader()if($reader.HasRows -eq $true){while ($reader.Read()){$rowID = $reader["ID"];$DatabaseName = $(if ($database_name_exist) { $reader["database_name"] } Else { "" });$timestamp = $reader["timestamp"];if($batch_text_exist -eq $true){$batch_text = $reader["batch_text"];$batch_text = $batch_text -replace "#tt[\d]+", "ttN";$batch_text = $batch_text -replace "@P[\d]+", "@PN";}if($sql_text_exist -eq $true){$sql_text = $reader["sql_text"];$sql_text = $sql_text -replace "#tt[\d]+", "ttN";$sql_text = $sql_text -replace "@P[\d]+", "@PN";}if($statement_exist -eq $true){$statement = $reader["statement"];$statement = $statement -replace "#tt[\d]+", "ttN";$statement = $statement -replace "@P[\d]+", "@PN";}# Обновляем данные в записи$sqlCmd_updateLogRecord = New-Object System.Data.SqlClient.SqlCommand$sqlCmd_updateLogRecord.Connection = $sqlConnectionForUpdate$sqlCmd_updateLogRecord.CommandTimeout = $sqlCmdTimeoutSeconds;$sqlCmd_updateLogRecord.CommandText = "UPDATE [dbo].[" + $tableWithLogName + "] SET" + $fieldsForUpdateLogRecord + "WHERE [timestamp (UTC)] = @timestamp" + $(if ($database_name_exist) {"AND [database_name] = @databaseName"} Else {""}) + "AND [ID] = @RowID";$newParam = $sqlCmd_updateLogRecord.Parameters.Add("RowID", $rowID);if($database_name_exist){$newParam = $sqlCmd_updateLogRecord.Parameters.Add("databaseName", $DatabaseName);}$newParam = $sqlCmd_updateLogRecord.Parameters.Add("timestamp", $timestamp);if($batch_text_exist){$newParam = $sqlCmd_updateLogRecord.Parameters.Add("new_batch_text", $batch_text);}if($statement_exist){$newParam = $sqlCmd_updateLogRecord.Parameters.Add("new_statement", $statement);}if($sql_text_exist){$newParam = $sqlCmd_updateLogRecord.Parameters.Add("new_sql_text", $sql_text);}$resultExec = $sqlCmd_updateLogRecord.ExecuteNonQuery();$lastRowID = $rowID;}} Else{$finish = $true;}$reader.Close();Write-Host "Последний обработанный идентификатор строки: " $rowID;} while($finish -ne $true)}catch{Write-Error $_.Exception.Message;}finally{$sqlConnection.Close();$sqlConnectionForUpdate.Close()}
Можно этот скрипт значительно ускорить за счет операций BulkInsert, кэширования в памяти и других способов, но есть ли смысл?
Используете другой подход? Было бы интересно узнать, пишите в комментариях.
Теперь мы готовы агрегировать данные для поиска проблемных запросов.
Смотрим результаты
Ничего сверхъестественного здесь нет. Просто группируем данные по тексту запроса и сортируем либо по CPU, либо по логическим чтениям.
Анализ запросов по CPU и чтениям
Предположим, что мы загрузили данные сессии “” в одноименную таблицу. Теперь нам лишь нужно получить самые тяжелые запросы по CPU. Выполним такой запрос.
SELECT TOP (10)DB_NAME([database_id]) AS [database_name],[sql_text],SUM([cpu_time]) [cpu_time],SUM([duration]) [duration],SUM([physical_reads]) [physical_reads],SUM([logical_reads]) [logical_reads],SUM([writes]) [writes],SUM([row_count]) [row_count]FROM [dbo].[HeavyQueryByCPU]GROUP BY DB_NAME([database_id]),[sql_text]ORDER BY [cpu_time] DESC
В итоге, имеем 10 самых тяжелых запросов по использованию ресурсов CPU.
Примерно такой же запрос был бы, если бы мы обрабатывали результаты сбора тяжелых запросов по чтениям.
Собранные логи по блокировкам также можно изучить запросом
Анализ блокировок
Собранную информацию о таймаутах и установленных блокировках можно анализировать по разному. Можно найти для каждого таймаута блокирующую для него транзакцию и конкретный запрос. Чтобы не усложнять пример, рассмотрим простейший случай.
Допустим, мы загрузили результаты сбора данных о таймаутах на блокировках в таблицу “LockAnalyze”, выполнили постобработку запросов. Далее вот таким простым запросом получаем список таймаутов и блокирующих сессий для него.
SELECTtimeouts.[timestamp],timeouts.[mode],timeouts.[transaction_id],timeouts.[database_id],timeouts.[resource_0],timeouts.[resource_1],timeouts.[resource_2]-- Информация что было заблокировано,locks.sql_text,locks.[timestamp] AS [lock_timestamp],locks.[transaction_id] AS [lock_transaction_id]FROM(SELECT[timestamp],[mode],[transaction_id],[database_id]-- Заблокированные ресурсы,[resource_0],[resource_1],[resource_2]FROM [dbo].[LockAnalyze]WHERE [name] = 'lock_timeout') timeoutsLEFT JOIN [dbo].[LockAnalyze] AS [locks]ON timeouts.[database_id] = locks.[database_id]AND timeouts.[resource_0] = locks.[resource_0]AND timeouts.[resource_1] = locks.[resource_1]AND timeouts.[resource_2] = locks.[resource_2]AND timeouts.[timestamp] > locks.[timestamp]AND locks.[name] = 'lock_acquired'
То есть мы попытались найти для каждого таймаута соответствующую установленную блокировку, которая стала причиной проблемы. Сопоставление сделали по ресурсам (поля resource_0, resource_1, resource_2), базе данных и учитывая время таймаута.
Конечно, такой анализ не даст точных результатов, а при большом объеме логов может показать множества лишней информации. В этом случае нужно будет усложнять запрос. Также может понадобиться добавить в сессию сбор событий Lock:Released.
Основное, что требуется здесь понять, так это общий подход к поиску причин таймаутов на блокировках. Наиболее эффективным способом определения причин появления проблем с блокировками является расследование “на горячую”, которое было описано в примерах выше.
И напоследок посмотрим ошибки SQL Server.
Анализ ошибок
Проанализируем самые частые ошибки на сервере СУБД и источники их возникновения.
SELECT TOP 10DB_NAME([database_id]) AS [database_name],[client_hostname],[client_app_name],[message],[username],[sql_text],COUNT(*) AS [error_count]FROM [dbo].[Errors]GROUP BYDB_NAME([database_id]),[client_hostname],[client_app_name],[message],[username],[sql_text]ORDER BY [error_count] DESC
Конечно, как устранить ошибки мы сразу не узнаем, но повод для расследования ситуации появится.
Запросы можно адаптировать под свои настройки расширенных событий.
А как же технологический журнал?
Конечно, использовать технологический журнал можно для анализа тяжелых запросов и блокировок, даже планы запроса можно собрать. Но вот незадача! Влияние ТЖ на производительность системы может быть на столько высоко, что фактически остановит основную работу. Именно поэтому встроенные средства SQL Server намного лучше для диагностики проблем на уровне СУБД.
Но, к сожалению, без технологического журнала все равно не обойтись. Вместе с простым мониторингом SQL Server он поможет решать такие задачи.
Поиск мест в модулях конфигурации
Допустим, мониторинг нашел, что подобный запрос находится в TOP 10 по нагрузке на CPU.
INSERT INTO #tt1 WITH(TABLOCK)(_Q_000_F_000, _Q_000_F_001, _Q_000_F_002, _Q_000_F_003)SELECTT1.Q_001_F_000_,T1.Q_001_F_001_,0x01,@P1FROM (SELECT1.0 AS Q_001_F_000_,@P2 AS Q_001_F_001_UNION ALLSELECT2.0,@P3UNION ALLSELECT3.0,@P4) T1
Как найти где именно он выполняется в конфигурации 1С? С помощью настройки ТЖ.
<?xml version="1.0" encoding="UTF-8"?><config xmlns="http://v8.1c.ru/v8/tech-log"><dump create="false"/><log location="<Путь к каталогу для сохранения логов>" history="48"><event><eq property="name" value="dbmssql"/><like property="Sql" value="%INSERT INTO%"/><like property="Sql" value="%SELECT%"/><like property="Sql" value="%0x01%"/><like property="Sql" value="%FROM (%"/><like property="Sql" value="%SELECT%"/><like property="Sql" value="%1.0%"/><like property="Sql" value="%UNION ALL%"/><like property="Sql" value="%SELECT%"/><like property="Sql" value="%2.0%"/><like property="Sql" value="%UNION ALL%"/><like property="Sql" value="%SELECT%"/><like property="Sql" value="%3.0%"/></event><property name="all"/></log></config>
В итоге, в одном из файлов логов мы получим модуль и строчку кода, откуда платформа генерирует этот запрос.
22:24.869011-1,DBMSSQL,6,process=rphost,p:processName=1C-Plus-MSOffice,OSThread=4760,t:clientID=12,t:applicationName=1CV8C,t:computerName=SRV-1C-MAIN,t:connectID=5,SessionID=2,Usr=DefUser,AppID=1CV8C,Trans=0,dbpid=59,Sql="INSERT INTO #tt1 WITH(TABLOCK) (_Q_000_F_000, _Q_000_F_001, _Q_000_F_002, _Q_000_F_003) SELECTT1.Q_001_F_000_,T1.Q_001_F_001_,0x01,?FROM (SELECT1.0 AS Q_001_F_000_,? AS Q_001_F_001_UNION ALL SELECT2.0,?UNION ALL SELECT3.0,?) T1p_0: 40181231000000p_1: 'Тест 1'p_2: 'Тест 2'p_3: 'Тест 3'",Rows=0,RowsAffected=3,Context='Форма.Вызов : Отчет.ВыгрузкаРезультатаКомпоновки.Форма.ФормаОтчета.Модуль.ВыгрузитьВAccessНаСервереОтчет.ВыгрузкаРезультатаКомпоновки.Форма.ФормаОтчета.Форма : 43 : РаботаСAccessКлиентСервер.ПолучитьОграниченияВыгрузкиБазы(,2,)ОбщийМодуль.РаботаСAccessСервер.Модуль : 55 : Возврат ВыгрузитьИсточникВБазуДанных(ОбщийМодуль.РаботаСAccessСервер.Модуль : 123 : Стр = ПолучитьСледующуюЗапись(ИсточникДанных, НомерЗаписи);ОбщийМодуль.РаботаСAccessСервер.Модуль : 302 : СледующаяЗапись = ИсточникДанных.Следующий();'
Для настройки ТЖ в этом случае нужно учитывать, что некоторые части SQL-запросов платформы могут изменяться (имена временных таблиц, имена полей вложенного запроса и др.). Поэтому лучше всего стараться использовать те части, которые точно не изменятся (имя таблиц или имена полей в базе, конструкции языка запросов и др).
Поиск ошибок, связанных с работой СУБД
Вообще, рекомендуется собирать информацию об исключительных ситуация на сервере 1С в постоянном режиме. Для этого настраивается технологический журнал с таким содержимым файла настроек.
<config xmlns="http://v8.1c.ru/v8/tech-log"><log location="<Путь к каталогу для сохранения логов>" history="168"><event><eq property="Name" value="EXCP"/></event><event><eq property="Name" value="EXCPCNTX"/></event><event><eq property="Name" value="ADMIN"/></event><event><eq property="Name" value="PROC"/></event><event><eq property="Name" value="ATTN"/></event><event><eq property="Name" value="QERR"/></event><event><eq property="Name" value="SCOM"/></event><event><eq property="Name" value="CONN"/></event><property name="all"></property></log></config>
Подобная настройка технологического журнала не создает заметной нагрузки на сервере и позволяет фиксировать события сбоев в работе его компонентов. При этом фиксируются и те ошибки, которые возникают при обращении к СУБД (таймауты на блокировках и др.).
Послесловие по ТЖ
Это только те задачи, которые можно решить с минимальной затратой ресурсов. В статье мы не будем подробно останавливаться на работе ТЖ, но с его помощью можно решить множество других вопросов, с которыми Extended Events не в силах помочь:
- Анализ и поиск проблем с управляемыми блокировками.
- Поиск узких мест производительности в коде конфигураций.
- Проверка работы сервера, кластера.
- И многое другое.
То есть без технологического журнала все равно никуда, но для диагностики проблем СУБД лучше использовать нативные инструменты.
Что еще можно / нужно собирать
Выше уже было сказано, что статья не является полным руководством, поэтому кратко рассмотрим что еще можно собирать для мониторинга. Кроме тех данных, что мы собирали с помощью расширенных событий, обязательно нужно мониторить:
- С помощью счетчиков производительности ОС Windows:
- Загрузку оборудования
- Внутренние показатели SQL Server.
- Статистику обслуживания базы данных:
- Один и более раз в день сохранять информацию о состоянии индексов в базу данных с логами с помощью Job\’а или другим способом. Можно использовать этот скрипт.
- Сохранять информацию о состоянии статистик в базу с логами также один или несколько раз в сутки. Например, этим скриптом.
- Фиксировать операции обслуживания индексов и статистик. Например, в этом скрипте обслуживания выделено место, где эту информацию можно записывать в базу (имя таблицы, имя обслуживаемого объекта, тип операции, дата запуска и дата завершения).
- Другую необходимую информацию:
- Статистику по ожиданиям.
- Размер баз.
- Размер таблиц.
- И многое другое.
Конечный вариант собираемых данных полностью зависит от целей мониторинга и должен быть адаптирован под Вашу ситуацию.
Конечно, можно использовать стандартные средства Windows и SQL Server, но можно взять в помощь какую-либо систему мониторинга. Например, Zabbix, или вообще все логи выгружать в ElasticSearch. Тут все зависит от потребностей.
Уровень Enterprise!
Вы дочитали до сюда с вопросом “А проще нельзя сделать”? Конечно, можно! Если бы выполнять мониторинг приходилось всегда через подобную ручную работу, то реагировать на проблемы производительности не всегда бы удавалось. Тем более на больших, высоконагруженных системах. Тут на помощь приходят инструменты мониторинга:
По крайней мере именно с этими инструментами приходилось работать за последние годы. На мой взгляд, самым продвинутым и эффективным остается PerfExpert, но это мое субъективное мнение.
Конечно, весь мониторинг можно организовать самостоятельно, но на это уйдет гораздо больше времени, а про сопровождение вообще лучше не говорить :).
Это еще не все
Мы рассмотрели преимущества использования Extended Events для диагностики работы СУБД и некоторые нюансы в контексте платформы 1С. Кратко пробежались по некоторым приемам работы с технологическим журналом и другим направлениям развития мониторинга.
Главное, что нужно понять, так это существующий большой разрыв в инструментах диагностики платформы 1С и SQL Server, причем не в пользу первой. Конечно, без ТЖ никуда, но для мониторинга СУБД и оперативной диагностики запросов, блокировок, взаимоблокировок и ошибок лучше использовать собственные инструменты SQL Server.