Обслуживание баз данных. Не так просто, как кажется
#SQL Server
#скрипты
#обслуживание
#проблемы
История начинается
Вы обслуживаете базу данных среднего или большого размера? Имею ввиду размер от 100 ГБ и больше. Если да, то, возможно, с проблемами обслуживания индексов и статистик Вы уже сталкивались, а описание кейса в статье будет Вам знакомо. Если же Вы счастливчик и имеете дело со скромными по размеру системами, то информация ниже может пригодиться Вам в будущем.
В любом случае, добро пожаловать! Рассказанный случай может быть полезен для всех.
Подопытная база
Главным героем сегодня будет “Бухгалтерия предприятия 3”. Точный релиз не важен, т.к. структура регистра бухгалтерии редко меняется. Да и любая конфигурация, имеющая в своем составе этот тип регистра, потенциально могла бы быть сегодня в центре внимания.
Интересуемые для нас характеристики подопытного:
- Размер базы 3 ТБ.
- Работа с регистром бухгалтерии ведется очень интенсивная. В сутки на основной таблице регистра выполняется порядка 800 тысяч операций записи (вставка и обновление данных), а также 12 млн. операций чтения.
- Регистр большого размера. Взгляните на состав его таблиц и их размеры (данные получены с помощью этого отчета). В таблице присутствует информация о количестве записей, а также размере данных и индексов. Общий размер регистра больше 120 ГБ! Как Вам? (Свертку не предлагать!)
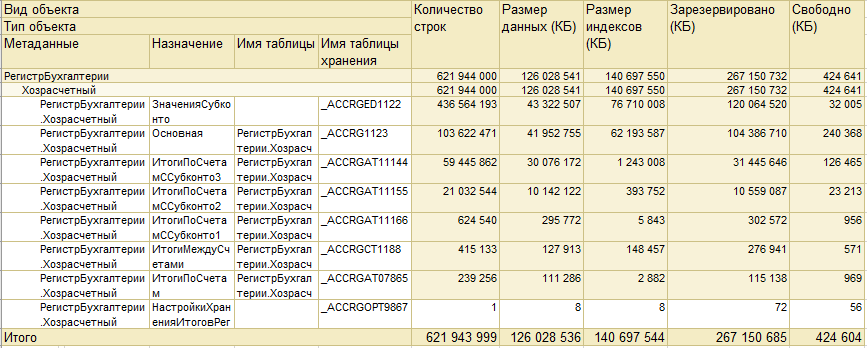
Плюс ко всему, в базе настроено обслуживание индексов и статистики вне рабочего времени, ночью. Обслуживание настроено с помощью этого решения. Обслуживание настроено с помощью этого решения.
В основном все работает хорошо и на производительность жалоб не поступает. APDEX в зеленой зоне (ох уж этот APDEX). Но иногда возникают странные проблемы с подвисанием и блокировками во время проведения / отмены проведения документов.
Двойная жизнь
Как это часто бывает, информационная система живет сложной жизнью. Днем она записывает / сохраняет документы при работе пользователей, а также формирует множество вариантов отчетов. Ночью же на сцену выходят “монстры”, называемые как “регламентные задания” с массовым изменением данных. Думаю, это обычная ситуация для многих.
В периоды отчетности и закрытия ситуация может меняться, но незначительно. Без каких-либо предпосылок и предупреждений, в любой день, с самого раннего утра начинают поступать жалобы, что документы проводятся очень медленно, а иногда и вовсе появляется ошибка таймаута на ожидании блокировки на уровне СУБД (в заявках, конечно, пользователи не так пишут, обычно просто “Не работает!”). Чем больше активных пользователей в системе, тем больше жалоб и критичность проблемы.
Сначала обычно начинают разбираться так:
- Есть ли зависшие сеансы 1С или сессии на SQL-сервер. Если есть, то “убивают” их, предварительно сохранив всю доступную информацию о сеансе или сессии.
- Зависает конкретное действие в базе или нет. Если конкретное, то уже проще - можно попытаться решить, оптимизировать или, как минимум, собрать информацию.
- Проверяем отработало ли обслуживание индексов и статистик ночью. Возможно, произошла ошибка при работе job’а и теперь придется разбирать последствия весь оставшийся день, возможно даже обслуживать часть таблиц “на горячую” (обожаю так делать!).
- Проверяем загрузку оборудования с помощью мониторинга (он же у вас есть, не так ли?). Если проблема там, то решаем вопрос с администраторами что и как делать. Тут может оказаться что был выпущен новый функционал и 1Сники решили “отопить” всю серверную за счет увеличения нагрузки на железо. Можете уточнить у своих коллег делают ли они так :)
- В отчаянии перезагружаем сервер.
Но в нашем случае ничего из вышеперечисленного не помогло! Жалобы продолжают поступать. Конечно, есть и другие способы диагностики, но не будем удлинять список, пойдем дальше.
Опять эти блокировки!
Причина, как Вы уже могли догадаться, была в регистре бухгалтерии. Но лежит она не на поверхности. При проведении документов они сразу же формирую проводки, отложенного проведения нет. Именно операция записи движения и является проблемой.
С помощью сбора данных со SQL Server, а именно причин таймаутов на блокировке (как собирать можно узнать здесь) выясняем, что проблемный запрос имеет следующий вид.
UPDATE T2 SET-- Итог по ресурсу "Сумма"_Fld9622 = T2._Fld9622 + T9._Fld9622,-- Итог по ресурсу "ВалютнаяСуммаДт"_Fld9623Dt = T2._Fld9623Dt + T9._Fld9623Dt, _Fld9623Ct = T2._Fld9623Ct+ T9._Fld9623Ct, _Fld9624Dt = T2._Fld9624Dt + T9._Fld9624Dt,-- Итог по ресурсу "ВалютнаяСуммаКт"_Fld9624Ct = T2._Fld9624Ct + T9._Fld9624Ct, _Fld9625Dt = T2._Fld9625Dt+ T9._Fld9625Dt, _Fld9625Ct = T2._Fld9625Ct + T9._Fld9625Ct,-- Итог по ресурсу "СуммаПРДт"_Fld9626Dt = T2._Fld9626Dt + T9._Fld9626Dt, _Fld9626Ct = T2._Fld9626Ct+ T9._Fld9626Ct, _Fld9627Dt = T2._Fld9627Dt + T9._Fld9627Dt,-- Итог по ресурсу "СуммаВРКт"_Fld9627Ct = T2._Fld9627Ct + T9._Fld9627CtFROM #tt24 T9 WITH(NOLOCK) -- Таблица с заранее подготовленными данными-- Таблица "ИтогиМеждуСчетами", именно в ней обновляются итоги данным запросомINNER JOIN dbo._AccRgCT1188 T2-- Соединения по:-- ПериодуON T9._Period = T2._Period-- СчетДТAND T9._AccountDtRRef = T2._AccountDtRRef-- Счет КТAND T9._AccountCtRRef = T2._AccountCtRRef AND T9._Fld9679RRef = T2._Fld9679RRef-- Валюта ДТAND ((T9._Fld9620DtRRef = T2._Fld9620DtRRef OR T9._Fld9620DtRRef IS NULL AND T2._Fld9620DtRRef IS NULL))-- Валюта КТAND ((T9._Fld9620CtRRef = T2._Fld9620CtRRef OR T9._Fld9620CtRRef IS NULL AND T2._Fld9620CtRRef IS NULL))-- Подразделение ДТAND ((T9._Fld9629DtRRef = T2._Fld9629DtRRef OR T9._Fld9629DtRRef IS NULL AND T2._Fld9629DtRRef IS NULL))-- Подразделение КТAND ((T9._Fld9629CtRRef = T2._Fld9629CtRRef OR T9._Fld9629CtRRef IS NULL AND T2._Fld9629CtRRef IS NULL))-- Служебный разделительAND T2._Splitter = @P9-- Фильтр по разделителю данныхWHERE (T2._Fld9659 = @P2)
При формировании записей движений платформа 1C выполняет множество запросов, ведь регистр бухгалтерии имеет сложную структуру и логику работы.
В этом случае выполняется обновление информации в таблице итогов оборотов между счетами. Во временной таблице есть подготовленная информация для расчета новых значений итогов (это те данные, которые сохраняются при записи движений и на которые нужно откорректировать итоги) и платформа соединяет ее с данными непосредственно таблицы итогов.
Вроде все хорошо, что же может пойти не так? Но если мы соберем дополнительную статистику, то увидим, что этот запрос выполняется порядка 30-60 секунд. То есть соединение данных двух таблиц выполняется очень долго, а в плане запроса обычно появляется операция “Table scan”. О ужас!
Поскольку для базы используется RCSI, то сканирование таблицы для обновления не блокирует всю таблицу. Лишь те записи, которые подходят под указанную аналитику (счет ДТ и КТ, подразделение ДТ и КТ, валюта ДТ и КТ и период (месяц)). Но так как сканирование выполняется до 60 секунд (а иногда и более), то при интенсивной работе есть вероятность появления таймаутов на таких блокировках, особенно если эта аналитика часто используется. Вот если бы RCSI не был бы включен, то блокировок было бы еще больше!
Но почему, почему запрос получился именно такой? Почему появились операции сканирования таблиц, ведь подходящие индексы для таблицы итогов есть? Вчера же все работало! Ох уж эта платформа 1С, она точно во всем виновата!
Почему так
Но почему? Почему так? Первое, что приходит в голову, так это проверить фрагментацию индексов у таблицы итогов регистра, вдруг обслуживание почему-то не отработало и поэтому SQL Server не использует индексы? СУБД считает их использование нецелесообразным, т.к. фрагментация слишком высокая. А если высокая, то затраты ресурсов при их использовании могут быть выше, чем старое доброе сканирование таблицы? Смотрим.
Проверим фрагментацию таким скриптом (взят из репозитория SQLServerTools).
SELECT OBJECT_NAME(ips.OBJECT_ID),i.NAME,ips.index_id,index_type_desc,avg_fragmentation_in_percent,avg_page_space_used_in_percent,page_countFROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'SAMPLED') ipsINNER JOIN sys.indexes i ON (ips.object_id = i.object_id)AND (ips.index_id = i.index_id)-- Отбор по имени таблицы итогов, у которой мы расследуем проблемуWHERE OBJECT_NAME(ips.OBJECT_ID) = '_AccRgCT1188'ORDER BY avg_fragmentation_in_percent DESC
Запустили и...
| Имя таблицы | Имя индекса | Идентификатор | Тип | Фрагментация, % |
|---|---|---|---|---|
| _AccRgCT1188 | _AccRgCT1188_ByDt_TRRRRRRRN | 2 | NONCLUSTERED INDEX | 9,937536 |
| _AccRgCT1188 | _AccRgCT1188_ByCt_TRRRRRRRN _ByDt_TRRRRRRRN | 3 | NONCLUSTERED INDEX | 9,223964 |
| _AccRgCT1188 | _AccRgCT1188_ByPeriod_T | 9 | CLUSTERED INDEX | 9,499961 |
Все ОК! Фрагментация ниже 10%, это отлично!
Что ж, проблем с индексами нет. Давайте тогда посмотрим на состояние статистики. озьмем простой скрипт для анализа статистики.
selecto.name AS [TableName],a.name AS [StatName],a.rowmodctr AS [RowsChanged],STATS_DATE(s.object_id, s.stats_id) AS [LastUpdate],o.is_ms_shipped,s.is_temporary,p.*from sys.sysindexes ainner join sys.objects oon a.id = o.object_idand o.type = 'U'and a.id > 100and a.indid > 0left join sys.stats son a.name = s.nameleft join (SELECTp.[object_id], p.index_id, total_pages = SUM(a.total_pages)FROM sys.partitions p WITH(NOLOCK)JOIN sys.allocation_units a WITH(NOLOCK) ON p.[partition_id] = a.container_idGROUP BYp.[object_id], p.index_id) p ON o.[object_id] = p.[object_id] AND p.index_id = s.stats_id-- Отбор по имени таблицы итогов, у которой мы расследуем проблемуWHERE o.name = '_AccRgCT1188'order bya.rowmodctr desc,STATS_DATE(s.object_id, s.stats_id) ASC
Выполняем и …
| Имя таблицы | Объект статистики | Количество записей с последнего обновления статистики | Дата последнего обновления статистики |
|---|---|---|---|
| _AccRgCT1188 | _WA_Sys_00000009_123123F | 186755 | 01.10.2019 12:00 |
| _AccRgCT1188 | _AccRgCT1188_ByPeriod_T | 173735 | 01.10.2019 12:00 |
| _AccRgCT1188 | _AccRgCT1188_ByDt_TRRRRRRRN | 173735 | 01.10.2019 12:00 |
| _AccRgCT1188 | _AccRgCT1188_ByCt_TRRRRRRRN | 173735 | 01.10.2019 12:00 |
| _AccRgCT1188 | _WA_Sys_00000001_123123F | 173735 | 01.10.2019 12:00 |
| _AccRgCT1188 | _WA_Sys_00000002_123123F | 173735 | 01.10.2019 12:00 |
| _AccRgCT1188 | _WA_Sys_00000003_123123F | 173735 | 01.10.2019 12:00 |
| _AccRgCT1188 | _WA_Sys_00000014_123123F | 173735 | 01.10.2019 12:00 |
| _AccRgCT1188 | _WA_Sys_00000008_123123F | 173735 | 01.10.2019 12:00 |
| _AccRgCT1188 | _WA_Sys_00000007_123123F | 173735 | 01.10.2019 12:00 |
| _AccRgCT1188 | _WA_Sys_00000006_123123F | 173735 | 01.10.2019 12:00 |
| _AccRgCT1188 | _WA_Sys_00000005_123123F | 173735 | 01.10.2019 12:00 |
| _AccRgCT1188 | _WA_Sys_00000004_123123F | 173735 | 01.10.2019 12:00 |
Статистика обновлялась давно (допустим, 2 дня назад), а записей с момента обновления статистики было изменено более 170 тысяч.
Бинго! Статистика стала неактуальной и SQL Server перестал использовать индексы в запросе. В начале статьи Вы могли видеть, что всего в таблице итогов между счетами примерно 415 тысяч записей. То есть, в таблице было потенциально изменено больше 30% всех данных, а статистика до сих пор не обновилась, что и не позволило СУБД использовать индексы должным образом.
Но почему? Скрипт ведь обслуживания есть, он отработал.
Да, обслуживание прошло ночью без ошибок, но до таблицы итогов между счетами оно просто не добралось! Сравните сами количество записей в других таблицах регистра и этой: 415 тыс. в таблице итогов и 103 млн. записей в основной таблице регистра. Разница существенная! Ночью были обслужены статистики больших таблиц, в которых изменения происходят чаще всего, а до мелких очередь просто не дошла. А ведь в базе есть не только регистр бухгалтерии, но и другие таблицы и пообъемнее!
В примере выше скрипт обслуживания статистик в первую очередь брал к обслуживанию те объекты, по которым больше всего изменилось записей. Даже если бы приоритет обслуживания определялся не по количеству изменений, а по % измененных строк от общего количества в таблице, то не факт, что очередь бы до нужного нам объекта дошла. По крайней мере на моей практике подход с определением приоритета обслуживания по % измененных записей часто давал сбой и делал не то, что следовало.
Может возникнуть вопрос: “Почему же проблема “плавает” и не возникает каждый день?”. Вопрос справедливый и ответ простой: массовые изменения в бухгалтерском регистре происходят не каждый день и зависят от каких-то неизвестных обстоятельств. Например:
- Внезапно понадобилось пересчитать итоги.
- Загрузить очень много документов.
- Перепровести регламентные операции закрытия.
- Да что угодно!
Плюс, в некоторых случаях обслуживание все же делает обновление статистики для этой таблицы, если в очереди нет других более тяжелых объектов к обслуживанию.
Как же быть в таких ситуациях?
Как быть
ля начала определимся что нужно сделать для оперативного исправления проблемы. Таблица небольшая, поэтому мы можем обновить статистику “на горячую”, ведь кратковременное замедление в период работы скрипта лучше, чем блокировки, подвисания и таймауты на блокировках до конца рабочего дня (а то и больше, ведь следующее ночное обслуживание тоже может не добраться до нужного нам объекта).
Обновляем статистику “на горячую”. Возьмем более простой вариант скрипта обслуживания статистики и выполним его с отбором по таблице.
SET NOCOUNT ON;DECLARE -- Служебные переменные@TableName SYSNAME,@IndexName SYSNAME,@SQL NVARCHAR(500);DECLARE todo CURSOR FORSELECT'UPDATE STATISTICS [' + SCHEMA_NAME([o].[schema_id]) + '].[' + [o].[name] + '] [' + [s].[name] + ']WITH FULLSCAN' + CASE WHEN [s].[no_recompute] = 1 THEN ', NORECOMPUTE' ELSE '' END + ';', [o].[name], [s].[name] AS [stat_name]FROM (SELECT[object_id],[name],[stats_id],[no_recompute],[last_update] = STATS_DATE([object_id], [stats_id]),[auto_created]FROM sys.stats WITH(NOLOCK)WHERE [is_temporary] = 0) sLEFT JOIN sys.objects o WITH(NOLOCK)ON [s].[object_id] = [o].[object_id]LEFT JOIN (SELECT[p].[object_id],[p].[index_id],[total_pages] = SUM([a].[total_pages])FROM sys.partitions p WITH(NOLOCK)JOIN sys.allocation_units a WITH(NOLOCK) ON [p].[partition_id] = [a].[container_id]GROUP BY[p].[object_id],[p].[index_id]) pON [o].[object_id] = [p].[object_id] AND [p].[index_id] = [s].[stats_id]LEFT JOIN sys.sysindexes siON [si].[id] = [s].[object_id] AND [si].[indid] = [s].[stats_id]WHERE [o].[type] IN ('U', 'V')AND [o].[is_ms_shipped] = 0-- Отбор по имени таблицы итогов, у которой мы расследуем проблемуWHERE o.name = '_AccRgCT1188'ORDER BY [rowmodctr] DESC;OPEN todo;WHILE 1=1BEGINFETCH NEXT FROM todo INTO @SQL, @TableName, @IndexName;IF @@FETCH_STATUS != 0BREAK;EXEC sp_executesql @SQL;ENDCLOSE todo;DEALLOCATE todo;
В нашем случае скрипт отработает достаточно быстро.
Окей, мы стабилизировали ситуацию! Блокировок больше нет, а система летает (и не падает)! Если бы таблица была очень большой, то потребовалось бы больше времени на обновление статистики, во время которого наблюдалось бы снижение производительности. Принимайте взвешенное решение, прежде чем запускать скрипт на продакшене.
Но как предотвратить подобную аварию в будущем?
Работая над обслуживанием базы некоторое время начинаешь собирать информацию об особенностях ее работы. К таким особенностям относится и наш случай. Мы можем создать отдельный план обслуживания для индексов и статистик, актуальное состояние которых критично для функционирования всей системы. Так и поступим в нашем случае: добавим план обслуживания нашей “особенной” таблицы и ее статистик, который будет работать параллельно основному плану обслуживания. Расписание также можно выбрать на свое усмотрение. Конкретно в этом случае был настроен запуск каждые 4 часа, так как таблица небольшая, а изменений по ней много. Основной работе обслуживание никак не мешало и занимало обычно от 5 до 15 секунд на рабочем сервере.
Скрипт для плана обслуживания можно сделать такой же, как и в выше. Правильно было бы также исключить из основного плана обслуживания те объекты, для которых созданы свои процессы обслуживания.
Теперь одной проблемой обслуживания базы данных меньше!
Нет базы - нет проблем
Все, что описано выше, необязательно должно случиться с Вами! Это лишь одна из возможных проблем, которая может поджидать при увеличении размера базы данных и ее чувствительности к качественному обслуживанию индексов и статистики.
Всю статью можно пересказать простыми словами: “Правильно обслуживайте индексы и статистику, тогда и проблем не будет”. Вот только не всегда однозначно можно сказать, как это сделать, а очевидные ответы бывают ошибочны. Те скрипты, что можно найти на просторах интернета или стандартные компоненты планов обслуживания SQL Server не являются полностью универсальными, как Вы могли убедиться из примера выше.
Следите за своими базами, держите обслуживание эффективным!