Базы данных. Несколько шагов до серьезного обслуживания
#DevOps
#SQL Server
#обслуживание
#оптимизация
#производительность
Об этом много сказано
Тема обслуживания баз данных (индексов и статистик) поднимается достаточно часто в разных статьях, официальной документации, на форумах и так далее. Обычно дается описание процессов обслуживания, зачем они нужны и какие бывают, на что влияют. И, конечно же, как сделать настройку обслуживания. Последнее обычно преподносится на базовом уровне, но, конечно, не всегда.
Сегодня мы снова коснемся этой темы, но несколько в ином ключе. Мы на практических примерах посмотрим на настройку обслуживания от простого случая до более продвинутого. Так можно будет проследить как меняется обслуживание при изменении требований к работе информационной системы.
Мы сосредоточимся на решении именно практических задач. Теорию Вы можете найти по ссылкам в конце статьи.
Общие слова
Прежде чем мы перейдем к примерам, определимся с тем, что будем делать.
Обслуживание подразумевает две больших части:
- Поддержание фрагментации индексов на приемлемом уровне. В идеале процент фрагментации у каждого индекса должен быть равен 0 или близок к этому значению.
- Состояние статистики должно быть в максимально в актуальном состоянии. При изменении строк в таблице, объекты статистики должны иметь гистограмму распределения значений, которая отражает состояние объектов базы наиболее актуальным образом.
Все это влияет на формируемые планы запросов. В самых общих чертах, если индекс имеет высокую фрагментацию или статистика знатно устарела, то оптимизатор SQL Server даже не будет пытаться использовать индекс и выполнит полное сканирование таблицы. Последнее, как Вы понимаете, не самая быстрая и оптимальная ситуация. Есть и другие последствия отсутствия обслуживания, но это совсем другая история.
Также сразу отметим, что никаких сторонних программ для настройки обслуживания мы использовать не будем. Чистый TSQL, возможно, в готовых скриптах и/или хранимых процедурах. Но никакого стороннего софта.
Итак, настало время первого примера!
Примеры, примеры, примеры
На старт, внимание, марш!
Типичное обслуживание
Когда речь заходит об обслуживании, то обычно начинают с создания плана обслуживания, где используют готовые компоненты. Для этого создаем план обслуживания через SQL Server Managment Studio в разделе “Managment ➡️ Maintenance Plans” с субпланом “FullMaintenance”.
Механизм планов обслуживания базируется на “обрезанной” версии SSIS, если так можно выразиться. Для использования готовых компонентов нужно использовать именно его.
Альтернативным вариантом является использование заданий (job’ов) агента SQL Server, просто указывая явно скрипты TSQL для выполнения.
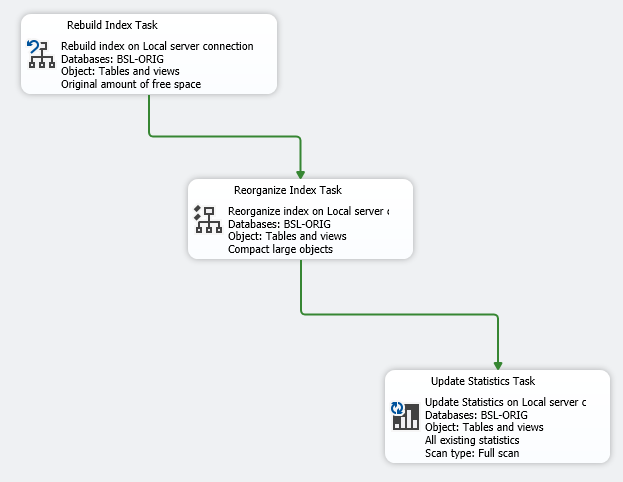
В созданный субплан добавляем три компонента. Выше Вы уже могли видеть схему субплана обслуживания.
Rebuild Index Task
Компонент перестроения индексов “Rebuild Index Task” имеет в себе большинство необходимых настроек для запуска простого обслуживания.
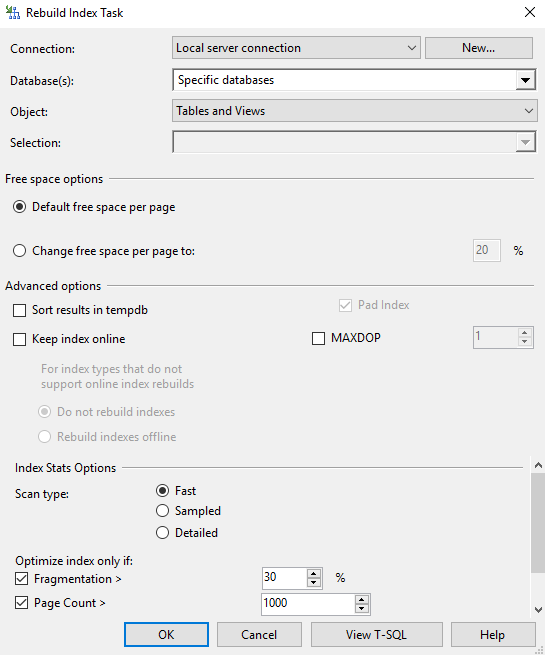
- Connection - указываем параметры соединения с базой данных, сервером СУБД. Обычно здесь остается стандартная настройка, останавливаться подробней не будем.
- Database(s) - указываем для какой базы (или списка баз) нужно выполнять обслуживание. Обычный фильтр.
- Object - здесь мы можем выбрать для каких объектов базы данных нужно выполнять обслуживание.
- Tables and Views - все объекты базы.
- Tables - таблицы базы, можно указать все или выбрать конкретные.
- Views - представления базы, можно указать все или выбрать конкретные.
- Free space options - параметр отвечает за то, сколько процентов свободного места нужно оставлять в каждой странице. По умолчанию используются стандартные параметры сервера, но это значение можно переопределить. Если оставлять некоторое место на страницах свободным, то можно уменьшить рост фрагментации индексов, т.к. изменения будут дописываться в существующие страницы и связанные данные меньше будут “раскидываться” между отдельными страницами. Подробнее читайте в документации, рассматривать это сегодня более детально не будем.
- Advaned options - это различные дополнительные настройки для более тонкого управления обслуживанием индексов.
- Sort results in tempdb - этот флаг включает хранение промежуточных результатов сортировки при формировании индекса. По умолчанию они хранятся в памяти или целевой файловой группе. По умолчанию он установлен в ЛОЖЬ.
- Keep index online - SQL Server поддерживает перестроение индексов в онлайн режиме, при котором работа с таблицей и индексом не блокируется во время выполнения обслуживания. По завершению перестроения выполняется переключение старого индекса на новый, что позволяет исключить блокирование работы запросов и выполнять обслуживание при минимальном размере технологического окна. Или при его полном отсутствии. Дополнительно к этому режиму указывают варианты действия для тех индексов, которые не поддерживают онлайн-обслуживание (например, если содержат типы text, ntext, image, filestream. Первые 3 считаются устаревшими, но все еще поддерживаются для совместимости). В момент переключения, конечно же, кратковременно создается блокировка на уровне схемы данных и есть различные сценарии обработки этой блокировки. Об этом подробней мы поговорим ниже.
- Do not rebuild - индексы без поддержки онлайн перестроения будут пропущены.
- Rebuild indexes offline - индекс без поддержки онлайн перестроения будет обслужен в обычном режиме с блокировкой работы с ним.
- Pad index - указать заполнение индекса. Определяет разреженность индекса. По умолчанию выключен. При включении настройка fillfactor применяется к страницам промежуточного индекса.
- MAXDOP - указываем степень параллелизма для операций обслуживания. Таким образом можно указать параметр, отличный от значения параметра всего сервера.
- Index Stats Options - параметры анализа индексов перед обслуживанием. Фактически это режимы просмотра для системной DMV sys.dm_db_index_physical_stats, которые влияют на работу некоторых фильтров и точность результатов анализа. Но зато поверхностный анализ позволяет ускорить запросы перед началом обслуживания. Детальный анализ потребует больше времени и создаст дополнительную нагрузку на сервер.
- Fash
- Sampled
- Detailed
- Oprimize index only if - дополнительные фильтры для обслуживаемых индексов.
- Fragmnetation > - фрагментация должна быть больше определенного процента. Общепринятым правилом считается, что перестроение нужно выполнять, если фрагментация выше 30%.
- Page Count - фильтр по размеру индекса. Указывается в количестве страниц. Каждая страница = 8 КБ.
Базовые настройки именно такие.
Reorganize Index Task
Компонент реорганизации индексов “Reorganize Index Task”. Позволяет выполнять операции реорганизации, которые требуют меньше ресурсов, чем перестроение. Также этот процесс выполняется без долгосрочных блокировок объекта и минимально влияет на текущую работу запросов. Обычно дефрагментация при таком способе выполняется для страниц конечного уровня, что делает такую операцию не всегда оптимальным вариантом.
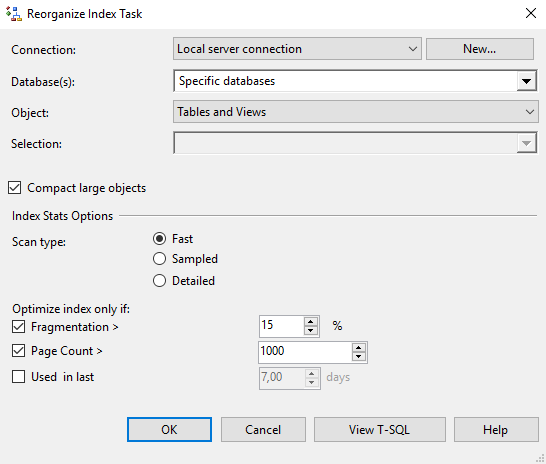
- Connection - указываем параметры соединения с базой данных, сервером СУБД. Обычно здесь остается стандартная настройка, останавливаться подробней не будем.
- Database(s) - указываем для какой базы (или списка баз) нужно выполнять обслуживание. Обычный фильтр.
- Object - здесь мы можем выбрать для каких объектов базы данных нужно выполнять обслуживание.
- Tables and Views - все объекты базы.
- Tables - таблицы базы, можно указать все или выбрать конкретные.
- Views - представления базы, можно указать все или выбрать конкретные.
- Compact large objects - освобождение пространства для таблиц и индексов, если возможно.
- Index Stats Options - параметры анализа индексов перед обслуживанием. Фактически это режимы просмотра для системной DMV sys.dm_db_index_physical_stats, которые влияют на работу некоторых фильтров и точность результатов анализа. Но зато поверхностный анализ позволяет ускорить запросы перед началом обслуживания. Детальный анализ потребует больше времени и создаст дополнительную нагрузку на сервер.
- Fast
- Sampled
- Detailed
- Oprimize index only if - дополнительные фильтры для обслуживаемых индексов.
- Fragmnetation > - фрагментация должна быть больше определенного процента. Общепринятым правилом считается, что перестроение нужно выполнять, если фрагментация выше 30%.
- Page Count - фильтр по размеру индекса. Указывается в количестве страниц. Каждая страница = 8 КБ.
- Used in last - фильтр по размеру индекса. Указывается в количестве страниц. Каждая страница = 8 КБ.
Настройки похожи на перестроение. Убраны параметры, которые для реорганизации просто не используются. Например MAXDOP, ведь операция реорганизации не распараллеливается как перестроение.
Update Statistics Task
Компонент обслуживания статистики “Update Statistics task”. Позволяет настроить обслуживание статистики в базе данных.
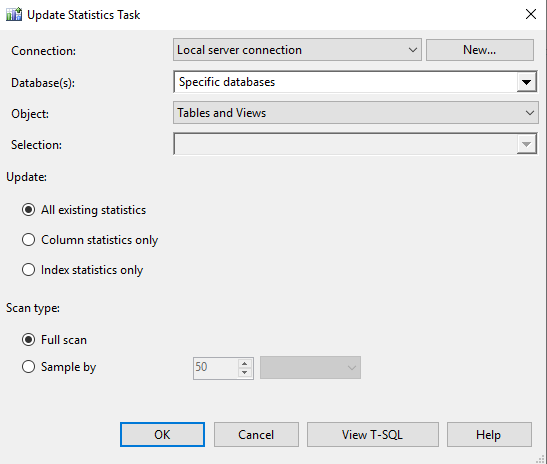
- Connection - указываем параметры соединения с базой данных, сервером СУБД. Обычно здесь остается стандартная настройка, останавливаться подробней не будем.
- Database(s) - указываем для какой базы (или списка баз) нужно выполнять обслуживание. Обычный фильтр.
- Object - здесь мы можем выбрать для каких объектов базы данных нужно выполнять обслуживание.
- Tables and Views - все объекты базы.
- Tables - таблицы базы, можно указать все или выбрать конкретные.
- Views - представления базы, можно указать все или выбрать конкретные.
- Update - режим обновления объектов статистики.
- All existing statistics - будут обновлены все объекты статистики.
- Column statistics only - обновление только статистики столбцов.
- Index statictis only - только статистику индексов.
- Scan type - тип сканирования данных таблицы для актуализации гистограммы распределения значений статистики.
- Full scan - полное сканирование всех значений.
- Sample by - для анализа будет использован только некоторый процент данных из таблицы, что позволит ускорить процесс обновления, но снизит точность.
На скриншоте ниже можно увидеть объекты статистики разных типов. Зеленым обведены объекты статистики, которые связаны с индексами. А объекты статистики с именем “WA_Sys*”, обведенные красным, это как раз служебные статистики столбцов, которые СУБД создает автоматически. Конечно, никто не мешает создать свой объект статистики, если в этом есть необходимость.
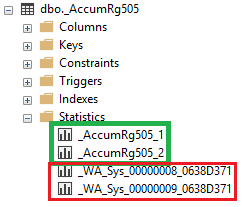
Чаще всего оставляют обновление всех объектов статистики, а не только тех, которые относятся к индексам. Также в абсолютном большинстве случаев достаточно оставить обновление статистики через анализ ограниченной выборки данных. Полное сканирование конечно хорошо, но на больших базах оно может выполняться много часов. Если база небольшая, то можно оставлять и полное сканирование, но нужно учитывать, что обновление статистики таким образом в некоторых случаях может создавать проблемы ввода-вывода, но опять же для больших баз.
Небольшой итог типичного обслуживания
Мы пробежались по основным настройкам каждого доступного компонента.
Предположим, что у нас типичная задача - небольшая база на SQL Server, работ ночью не ведется и в качестве технологического окна у нас время с 21:00 до 06:00. Идеально! Тогда настроим запуск обслуживания как на схеме выше, чередуя операции следующим образом:
- Перестроение индексов с указанием нужной базы и выбрав все таблицы и представления. При этом не используем онлайн-перестроение, оставляем отключенной сортировку в TempDB и так далее. В общем все настройки стандартные как на скрине выше, разве что MAXDOP можно поставить максимальный, пусть все ресурсы сервера будут выделены под перестроение.
- Вторым шагом реорганизация индексов. Также оставляем все настройки по умолчанию. Реорганизацию оставляем именно вторым шагом, т.к. в первую очередь нужно выполнить обслуживание индексов, у которых фрагментация выше 30%.
- И последней операцией устанавливаем обновление статистики. Пусть выполняется для всех объектов статистики и методом полного сканирования.
Также рекомендую добавить еще один субплан обслуживания для обновления статистики в дневное время, чтобы сгладить изменения в базе и помочь оптимизатору запросов актуальной статистикой. Например, установить запуск операции ежедневно в 13:00 (например, сориентироваться на обеденное время сотрудников). Настройки такие же, как и у обновления статистики в ночное время.

Так как база небольшая, то, скорее всего, весь процесс обслуживания завершится за 30-60 минут ночью и за 5-15 минут днем, а может и еще быстрее.
Плюсы:
- Простота настройки
Минусы:
- Отсутствие контроля выполнения
- Блокирование работы запросов в момент обслуживания
- Нет возможности проанализировать результаты выполнения обслуживания в динамике, нет истории работы обслуживания
Но если база небольшая, то все перечисленные минусы несущественны. Что такое небольшая база? Понятие относительное :). Главное, что нужно понять, так это если такое обслуживание Вас полностью устраивает, то делать что-то более сложное нет смысла.
Первые проблемы
Какое-то время все шло хорошо, но от бизнеса появилось новое требование: в ночное время обслуживание не должно мешать работе информационной системы. Например, могли появиться важные регламентные задания по интеграции, расчетам и так далее.
Выше мы уже говорили, что SQL Server поддерживает онлайн-перестроение индексов и мы можем его использовать для тех объектов, которые это поддерживают. Те объекты, для которых онлайн-перестроение нельзя выполнить из-за использования legacy-типов в полях (text, ntext, image), будут обслужены обычным образом с блокировкой работы с ними. Так что от всех проблем мы не избавимся, но других настроек в стандартном компоненте нет. Поэтому следует выполнить следующие изменения:
- В шаге перестроения индексов, который выполняется в ночное время, установить использование онлайн перестроения. По сравнению с обычной операцией обслуживания онлайн перестроение требует больше ресурсов по CPU и по использованному месту, да и лог транзакций при полной модели восстановления будет заполнен больше. Такова цена беспрерывной работы запросов.
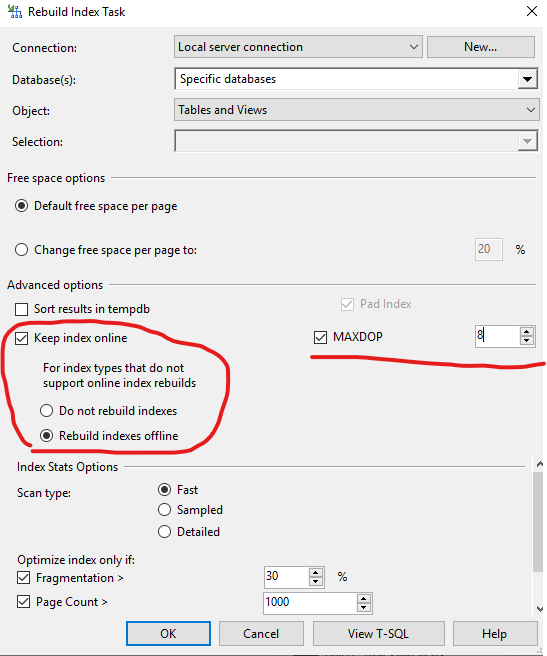
- Степень параллелизма желательно установить ограниченным значением, чтобы CPU не был загружен на 100% во время обслуживания. Ведь блокировки не единственная проблема, которая может помешать работе информационной системе. Высокая нагрузка от обслуживания тоже может остановить работу. Общая рекомендация поставить MAXDOP = 30% от общего количества ядер. Например, если на сервере 24 ядра, то под перестроение индексов выделить только 8.
- Остальные настройки оставляем как есть.
Тут также подведем небольшой итог.
Плюсы:
- Простота настройки
- Минимальное влияние на работу системы во время обслуживания
Минусы:
- Отсутствие контроля выполнения
- Блокирование работы запросов в момент обслуживания для тех объектов, в которых онлайн перестроение невозможно
- Нет возможности проанализировать результаты выполнения обслуживания в динамике, нет истории работы обслуживания
Опять же, если последние 3 причины не критичны, то все отлично!
Большой шаг
Компания развивается, и информационная база растет. У нас появились большие таблицы и много, а технологическое окно уменьшилось: с 21:00 до 23:00. Появились склады, которые работают 24/7. Кроме этого остается старая проблема с объектами, которые не поддерживают онлайн перестроение. Мы должны их обслуживать так, чтобы они минимально создавали блокировки. Кроме этого, нужно гарантировать, что обслуживание не выйдет за пределы установленного технологического окна с 21:00 до 23:00.
К сожалению, стандартными компонентами обслуживания, которыми пользовались до этого момента, данную задачу решить уже нельзя. Поэтому мы пойдем другим путем. Мы создадим служебную базу обслуживания и мониторинга с именем “SQLServerMaintenance”, а далее наполним ее объектами следующим скриптом.
Этот скрипт взят отсюда. Там же есть примеры использования, описания процедур и их параметров, а также другая связанная информация. Для актуальной версии следите за обновлениями. Также никто не мешает Вам дорабатывать эти скрипты для себя.
Инструмент готов, а теперь нужно заменить компоненты обслуживания на свои скрипты. И вот как это будет выглядеть.
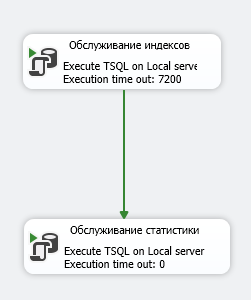
Вместо трех шагов теперь только 2, в каждом свои скрипты для выполнения операций. На первом шаге используем такой скрипт:
EXECUTE [SQLServerMaintenance].[dbo].[sp_IndexMaintenance]@databaseName = 'BSL-ORIG'-- Разрешаем запуск скрипта с 21:00:00 до 22:30:00,@timeFrom = '21:00:00',@timeTo = '22:30:00'-- 1 - обслуживать только те объекты, которые поддерживают онлайн-перестроение,@useOnlineIndexRebuild = 1-- Процент фрагментации, с которого будет выполняться обслуживание,@fragmentationPercentMinForMaintenance = 10-- Процент фрагментации с которого начинается полное перестроение.-- Все, что между 10 и 30 будет обслуживаться операцией реорганизации,@fragmentationPercentForRebuild = 30-- Степень параллелизма для операций перестроения оставляем равной 8,@maxDop = 8-- Настраиваем поведение онлайн-перестроения в ситуациях, когда переключение индекса на новый блокируется-- другими запросами-- 1 - операция обслуживания завершит себя по истечении таймаута ожидания.,@onlineRebuildAbortAfterWaitMode = 1-- Время ожидания операции онлайн перестроения перед прерыванием работы. Ставим 15 минут,@onlineRebuildWaitMinutes = 15
В скрипте мы указываем имя базы, для которой устанавливаем обслуживание и диапазон времени, в который можно выполнять операции обслуживания.
Кроме этого указываем, что нужно обслуживать только те объекты, которые поддерживают онлайн перестроение (параметр @useOnlineIndexRebuild). Также устанавливаем, что обслуживание нужно начинать только с 10% фрагментацией (@fragmentationPercentMinForMaintenance), а полное перестроение только при 30% значении фрагментации индекса (@fragmentationPercentForRebuild). Таким образом, реорганизация индекса будет применяться, если фрагментация находится в диапазоне между 10% и 30%.
Дополнительно к этому установим особые параметры онлайн обслуживания:
- При блокировании обслуживания другими запросами отдаем приоритет именно им. То есть по истечении таймаута операция обслуживания завершит сама себя (@onlineRebuildAbortAfterWaitMode).
- Время ожидания при этом установим в 15 минут (@onlineRebuildAbortAfterWaitMode).
Это должно решить все перечисленные выше задачи.
Для обслуживания статистики будем использовать следующий скрипт.
EXECUTE [SQLServerMaintenance].[dbo].[sp_StatisticMaintenance]@databaseName = 'BSL-ORIG',@timeFrom = '21:00:00',@timeTo = '22:30:00'-- 0 устанавливаем режим анализа выборки данных,-- 1 - режим полного сканирования,@mode = 1
Также указываем время работы скрипта и режим полного сканирования.
На первом шаге мы обязательно установим таймаут выполнения операции в 2 часа. Это соотносится с указанным в настройках диапазоном времени с 21:00 до 22:30 (1.5 часа). Таймаут в 2 часа это последний рубеж защиты, чтобы процедуры обслуживания не вышли за 23:00. Такое может произойти, если индекс начал операцию перестроения или реорганизации в 22:20 и к 23:00 не завершился, то таймаут выполнения команды ее прервет “насильно”.
При этом для операции обновления статистики таймаут выполнения мы не ставим, т.к. она не мешает работе других запросов. При этом если обслуживание индексов работало до 23:00 (с таймаутом или без), то обслуживание статистик не будет запущено. Считаем это проблемными ситуациями и они не должны возникать часто.
Также добавим дополнительный субплан для обслуживания индексов, которые не поддерживают онлайн перестроение. Считаем, что таких объектов не много и их можно обслуживать раз в неделю. Для этого добавим субплан с запуском раз в неделю, например в субботу в 23:00 и отдаем на работу скрипта 30 минут. Скрипт будет таким. Заменяем параметр “@useOnlineIndexRebuild” и убираем настройки, связанные с онлайн перестроением.
EXECUTE [SQLServerMaintenance].[dbo].[sp_IndexMaintenance]@databaseName = 'BSL-ORIG'-- Разрешаем запуск скрипта с 23:00:00 до 23:30:00,@timeFrom = '23:00:00',@timeTo = '23:30:00'-- (2) - обслуживание только тех объектов, в которых онлайн-перестроение не поддерживается.,@useOnlineIndexRebuild = 2-- Процент фрагментации, с корого будет выполняться обслуживание,@fragmentationPercentMinForMaintenance = 10-- Процент фрагментации с которого начинается полное перестроение.-- Все, что между 10 и 30 будет обслуживаться операцией реорганизации,@fragmentationPercentForRebuild = 30-- Степень параллелизма для операций перестроения оставляем равной 8,@maxDop = 8
Таймаут для операции установим в 1 час, то есть в 00:00 операция будет завершена в любом случае.
И последнее изменение - это дополнительные шаги обслуживания статистики. Ранее мы запускали в дневное время отдельное обновление статистики, а теперь будем выполнять это 3 раза (не считая основного ночного обслуживания): в 06:00, 13:00 и в 18:00. Отключаем ограничения времени выполнения и режим обновления теперь выполняем через выборку данных, а не полным сканированием.
EXECUTE [SQLServerMaintenance].[dbo].[sp_StatisticMaintenance]@databaseName = 'BSL-ORIG'-- 0 устанавливаем режим анализа выборки данных,-- 1 - режим полного сканирования,@mode = 0
Так как полное сканирование не используется, то даже для многотеррабайтных баз эта операция будет выполняться за 5-30 минут. Поэтому ограничения выполнения или таймаутов выполнения устанавливать не будем.
Готово! Небольшие итоги:
Плюсы:
- Минимальное влияние на работу запросов во время обслуживания (как по блокировкам, так и по нагрузке на базу).
- Максимально актуальная статистика во время всего рабочего дня.
- Полный контроль над выполняемыми операциями. Приоритет отдается выполняемым запросам, а не обслуживанию. Работа информационной системы не будет нарушена.
- Практически полное покрытие задач обслуживания баз данных в большинстве мелких, средних и крупных баз данных.
Минусы:
- Более сложная схема настройки, требующая понимания работы процессов обслуживания и их сопровождения.
- Необходимость прочитать инструкции и документацию по SQL Server в нештатных ситуациях.
- Желательны навыки работы с TSQL.
Может ли потребоваться изменять обслуживание еще как-то?
А вот и полная модель
Настает момент, когда для задач отказоустойчивости и надежности базу данных переключают в полную модель восстановления. Это позволяет восстановить базу данных из бэкапа на любой момент времен и не потерять данные в случае внезапного падения.
Рассматривать шаги для безопасного перевода баз в полную модель мы не будем. Основное что отметим - в таком режиме все изменения сохраняются в лог транзакций и остаются там до тех пор, пока он не будет бэкапирован. Важно заметить, что только бэкап лога транзакций помечает их готовыми к удалению из файла лога. Полный бэкап файл лога транзакций не очистит.
Но использование полной модели накладывает особенности в работе обслуживания. Может случиться так, что перестроение индексов может заполнить лог транзакций, что остановит все операции модификации данных в базе. Другими словами, информационная система перестанет работать.
Чтобы этого не случилось - установим ограничения на использование файла логов транзакций. Дополним предыдущий скрипт параметром ограничения. Скрипт тот же, только добавили один параметр в конце.
EXECUTE [SQLServerMaintenance].[dbo].[sp_IndexMaintenance]@databaseName = 'BSL-ORIG'-- Разрешаем запуск скрипта с 21:00:00 до 22:30:00,@timeFrom = '21:00:00',@timeTo = '22:30:00'-- 1 - обслуживать только те объекты, которые поддерживают онлайн-перестроение,@useOnlineIndexRebuild = 1-- Процент фрагментации, с которого будет выполняться обслуживание,@fragmentationPercentMinForMaintenance = 10-- Процент фрагментации с которого начинается полное перестроение.-- Все, что между 10 и 30 будет обслуживаться операцией реорганизации,@fragmentationPercentForRebuild = 30-- Степень параллелизма для операций перестроения оставляем равной 8,@maxDop = 8-- Настраиваем поведение онлайн-перестроения в ситуациях, когда переключение индекса на новый блокируется-- другими запросами-- 1 - операция обслуживания завершит себя по истечении таймаута ожидания.,@onlineRebuildAbortAfterWaitMode = 1-- Время ожидания операции онлайн перестроения перед прерываниеем работы. Ставим 15 минут,@onlineRebuildWaitMinutes = 15-- !!!-- Разрешаем использование только 50% файла лога транзакций.-- Если лог транзакций заполнен на больший процент, то новые объекты обслуживаться не будут,@maxTransactionLogSizeUsagePercent = 50-- Можно также установить ограничение явно в мегабайтах--,@maxTransactionLogSizeMB bigint = 0-- !!!
Параметры @maxTransactionLogSizeUsagePercent и @maxTransactionLogSizeMB как раз и решают эту задачу. Но нужно учитывать, что проверка выполняется перед началом выполнения операции обслуживания. Если индекс начал перестраиваться, то ограничение на текущий процесс уже не повлияет. Поэтому также рекомендуется спланировать резерв места на диске с файлом лога транзакций. А если, мало ли, размер логов при перестроении может превысить 2 ТБ, то нужно создать несколько файлов логов транзакций, чтобы обойти это ограничение. Да, максимальный размер одного файла лога транзакций равен 2 ТБ.
Разделяй и властвуй
В некоторых случаях есть смысл большие индексы обслуживать не ежедневно, а раз в неделю и, например, только полным перестроением. Для этого внесем следующие изменения:
- В ежедневном плане обслуживания индексов установим условие на максимальный размер обслуживаемых объектов. Расписание установим с понедельника по субботу. Можно установить нижнюю (@maxIndexSizePages) и верхнюю (@maxIndexSizePages) границу. В примере мы ставим условие только на макс. размер объекта. В скрипте ниже объекты размером 100 ГБ обслуживаться не будут.EXECUTE [SQLServerMaintenance].[dbo].[sp_IndexMaintenance]@databaseName = 'BSL-ORIG'-- Разрешаем запуск скрипта с 21:00:00 до 22:30:00,@timeFrom = '21:00:00',@timeTo = '22:30:00'-- 1 - обслуживать только те объекты, которые поддерживают онлайн-перестроение,@useOnlineIndexRebuild = 1-- Процент фрагментации, с которого будет выполняться обслуживание,@fragmentationPercentMinForMaintenance = 10-- Процент фрагментации с которого начинается полное перестроение.-- Все, что между 10 и 30 будет обслуживаться операцией реорганизации,@fragmentationPercentForRebuild = 30-- Степень параллелизма для операций перестроения оставляем равной 8,@maxDop = 8-- Настраиваем поведение онлайн-перестроения в ситуациях, когда переключение индекса на новый блокируется-- другими запросами-- 1 - операция обслуживания завершит себя по истечении таймаута ожидания.,@onlineRebuildAbortAfterWaitMode = 1-- Время ожидания операции онлайн перестроения перед прерыванием работы. Ставим 15 минут,@onlineRebuildWaitMinutes = 15-- !!!-- Разрешаем использование только 50% файла лога транзакций.-- Если лог транзакций заполнен на больший процент, то новые объекты обслуживаться не будут,@maxTransactionLogSizeUsagePercent = 50-- Макс. размер обслуживаемых объектов будет равен 50 ГБ.-- Размер устанавливается в количестве страниц по 8 КБ.-- 50 ГБ = 6553600 страниц,@maxIndexSizePages = 6553600
- Добавим еще один субплан обслуживания с теми же операциями, что и в ежедневном плане обслуживания, но в скрипте обслуживания индексов снимем ограничение на макс. размер индекса.
Это позволит разделить обслуживание и избавится от массивных операций изменения в будние дни. Тут стоит отметить, что нужно понимать последствия таких решений. Предварительно нужно проанализировать что это за таблицы и как изменение стратегии обслуживания повлияет на работу информационной системы.
Есть и более точечный вариант настройки обслуживания, в котором ограничения будут опираться не на размер объектов, а на конкретные объекты. Например, можно добавить такое условие в процедуру обслуживания индексов:
-- Отбор по конкретной таблице,@ConditionTableName = 'IN (''_AccumRg1265'',''_AccumRg505'')'
или даже поставить отбор на конкретный индекс:
-- Отбор на конкретный индекс (отбор по таблице в этом случае не обязателен),@ConditionIndexName = '= ''_AccumRg505_1'''
Для таких точечных операций обслуживания можно задать свое расписание, свои таймауты выполнения и так далее.
Слишком большие объекты
Следующая проблема, которая может появиться в больших базах - это обслуживание ооооооочень больших, огромных объектов в пределах окна обслуживания. Например, у нас есть 2 часа на обслуживание индексов. Но что, если для перестроения индекса, размер которого 1 ТБ, нужно 5 часов.
Конечно, в онлайн режиме блокировок это не создаст, но замедление работы с индексом или выделяемые ресурсы для такого перестроения могут косвенно влиять на другие запросы. Кроме этого, файл лога транзакций будет заполняться полностью и даже дополнительные файлы могут не спасти ситуацию.
Тут на помощь приходят возобновляемые операции перестроения индексов, доступных со SQL Server 2017. Работает это так:
- Вы запускаете операцию перестроения индекса в онлайн режиме, указав параметр RESUMABLE = ON.ALTER INDEX PK_1ON [dbo].[_Acc1]REBUILDWITH (ONLINE = ON, RESUMABLE = ON);GO
- Процесс перестроения выполняется, пока Вы не прервете его явно командой завершения сессии (например, если таймаут сработал) или не указав остановку явно.ALTER INDEX PK_1 ON [dbo].[_Acc1] PAUSE
- После остановки операции файл журнала транзакций может быть освобожден после выполнения бэкапа логов. Да, перестроение индекса еще не завершено, но освободить файл журнала транзакций можно.
- Можно проверить список операций перестроения, доступных для продолжения, а также состояние прогресса перестроенияSELECTtotal_execution_time,percent_complete,name,state_desc,last_pause_time,page_countFROM sys.index_resumable_operations;
- Возобновляем операцию перестроения при необходимости. Например, в следующем технологическом окне обслуживания.ALTER INDEX PK_1 ON [dbo].[_Acc1] RESUME
- Или можно прервать операцию окончательно.ALTER INDEX PK_1 ON [dbo].[_Acc1] ABORT
Это позволит выполнять даже самые тяжелые операции в заданное окно обслуживания, хоть и за несколько дней. А также обезопасить себя от переполнения лога транзакций.
В контексте нашей служебной базы использование возобновляемого перестроения включается через параметр @useResumableIndexRebuildIfAvailable, который может быть задействован только при использовании операций онлайн перестроения индексов. В примере ниже мы поставим отбор для конкретного индекса, по которому нужно выполнять возобновляемое перестроение. Использовать подобное обслуживание для всех объектов в базе не имеет смысла. Последние два параметра тут основные для примера.
EXECUTE [SQLServerMaintenance].[dbo].[sp_IndexMaintenance]@databaseName = 'BSL-ORIG'-- Разрешаем запуск скрипта с 21:00:00 до 22:30:00,@timeFrom = '21:00:00',@timeTo = '22:30:00'-- (2) - обслуживание только тех объектов, в которых онлайн-перестроение не поддерживается.,@useOnlineIndexRebuild = 2-- Процент фрагментации, с которого будет выполняться обслуживание,@fragmentationPercentMinForMaintenance = 10-- Процент фрагментации с которого начинается полное перестроение.-- Все, что между 10 и 30 будет обслуживаться операцией реорганизации,@fragmentationPercentForRebuild = 30-- Степень параллелизма для операций перестроения оставляем равной 8,@maxDop = 8-- Включаем возобновляемое перестроение индексов,@useResumableIndexRebuildIfAvailable = 1-- И только для конкретного индекса,@ConditionIndexName = '= ''_AccumRg505_1'''
Но есть и подводный камень! Если индекс находится в списке операций возобновляемых операций перестроения, то его нельзя удалить или перестроить другими операциями. Нужно либо завершить перестроение, либо прервать его окончательно.
Если во время работы скрипта из примера операция будет прервана по таймауту (или вручную), то при следующем запуске этого же скрипта будет действовать такой алгоритм:
- Проверяются списки объектов, для которых нужно выполнить возобновление перестроения. При этом учитываются условия по таблицам и индексам.
- Если такая операция есть в списке, то возобновляем ее работу. Если нет, то идем дальше.
- Далее выполняем обычные операции обслуживания. При этом если на прошлом шаге было завершено возобновляемое перестроение индекса, то на следующих шагах обслуживания эти объекты будут пропущены. Это сделано для того, чтобы один и тот же объект не был перестроен дважды.
Этот механизм является спасительным для многих больших баз данных. А некоторые люди еще говорят, что разницы между SQL Server 2012 и SQL Server 2019 нет, вот им пример :)
Да здравствует AlwaysOn
При включении групп высокой доступности AlwaysOn появляется особый нюанс - если реплика становится недоступной для отправки изменений, то записи в файле лога транзакций не будут удалены даже после выполнения бэкапа лога транзакций. Это сделано для того, чтобы при возобновлении передачи данных не потерять транзакции, которые еще не ушли на копии баз, реплики.
Для обслуживания это может означать, что при каких-то авариях с передачей данных в AlwaysOn лучше повременить с обслуживанием, пока передача данных не будет восстановлена и файл лога транзакций не будет освобождён.
Подобная ситуация может возникнуть не только при сбое связи, а, например, если после перестроения 1 ТБ индекса эти изменения будут отправляться на копии. Пока все изменения после перестроения не “уйдут” на копии, то лог транзакций также не сможет быть освобожден.
Но на самом деле решение этой проблемы у нас уже есть. Выше мы уже говорили про параметры ограничения файла лога транзакций в полной модели восстановления, а также кратко прошлись по созданию резерва для логов. Этот же подход нужно использовать и в нашем случае.
Также нужно понимать, что операции обслуживания нужно выполнять только в первичном узле (основной базе), а на копиях баз настраивать обслуживание просто нет смысла. Это же копии в режиме “только для чтения”. Перестроение индексов или обновление статистик там недоступно.
Информацию про использование AlwaysOn Вы можете посмотреть здесь, в том числе описание некоторых нюансов и настроек.
Комбо!
И напоследок - комбо! Все вышеописанные подходы к настройке можно комбинировать как Вам угодно, главное не делать это вслепую! И лучше всего усложнять обслуживание только по необходимости, подтверждая свои шаги через анализ логов обслуживания.
Если Вы будете использовать служебную базу, о конторой идет речь в этой статье, то все операции перестроения индексов или обновления объектов статистики логируются. Например, в таблице “MaintenanceActionsLog” можно посмотреть когда, как и почему объект обслуживался.

Вы будете знать обслуживался ли он онлайн, было это перестроение или реорганизация, какой процент фрагментации был на момент обслуживания, сколько записей изменилось с момента обновления статистики, какая SQL-команда использовалась, длительность операции и вообще завершилась ли операция. Операция обслуживания будет взята под полный контроль!
Также может возникнуть необходимость запускать скрипты перестроения индексов параллельно друг другу, для ускорения обслуживания, например. Но тут возникает нюанс! Если есть активная операция перестроения индекса, то DMV sys.dm_db_index_physical_stats не сможет получить текущее состояние индексов, пока перестроение не будет завершено. В итоге операции перестроения параллельно и не будут запущены. Но и тут есть выход!
Вы можете запустить сбор информации о состоянии объектов базы данных заранее через команду:
EXECUTE [SQLServerMaintenance].[dbo].[sp_FillDatabaseObjectsState]@databaseName = 'BSL-ORIG'
Команда вызовет sys.dm_db_index_physical_stats и сохранит результаты в таблицу “DatabaseObjectsState”. А в скриптах перестроения индексов можно указать параметр @usePreparedInformationAboutObjectsStateIfExists, тогда повторного анализа объектов выполнено не будет и обслуживание будет использовать информацию из таблицы “DatabaseObjectsState”.
-- Используем ранее сохраненную информацию о состоянии объектов базы данных,@usePreparedInformationAboutObjectsStateIfExists = 1
Но есть нюанс! Информация об объектах базы должна быть собрана в последние 12 часов на момент вызова обслуживания. Иначе информация будет считаться устаревшей и запустится обычный анализ объектов.
Таким образом, можно запускать 2 и более процессов обслуживания индексов, не опасаясь их блокировки друг другом на этапе анализа объектов базы.
Как отслеживать качество обслуживания
Это отдельная тема, но в самом простом виде можно действовать так:
- Следить, чтобы статистика была максимально актуальной. Например, таким скриптом. Так вы увидите есть ли объекты, по которым статистика давно не обновлялась, а также объекты, по которым изменения накапливаются очень быстро. Возможно, нужно делать обновление статистики для них чаще нескольких раз в день.selecto.name AS [TableName],a.name AS [StatName],a.rowmodctr AS [RowsChanged],STATS_DATE(s.object_id, s.stats_id) AS [LastUpdate],o.is_ms_shipped,s.is_temporary,p.*from sys.sysindexes ainner join sys.objects oon a.id = o.object_idand o.type = 'U'and a.id > 100and a.indid > 0left join sys.stats son a.name = s.nameleft join (SELECTp.[object_id], p.index_id, total_pages = SUM(a.total_pages)FROM sys.partitions p WITH(NOLOCK)JOIN sys.allocation_units a WITH(NOLOCK) ON p.[partition_id] = a.container_idGROUP BYp.[object_id], p.index_id) p ON o.[object_id] = p.[object_id] AND p.index_id = s.stats_idorder bya.rowmodctr desc,STATS_DATE(s.object_id, s.stats_id) ASC
- Следить за фрагментацией индексов. Можно использовать уровень детализации “DETAILED” для более точных данных.SELECT OBJECT_NAME(ips.OBJECT_ID),i.NAME,ips.index_id,index_type_desc,avg_fragmentation_in_percent,avg_page_space_used_in_percent,page_countFROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'SAMPLED') ipsINNER JOIN sys.indexes i ON (ips.object_id = i.object_id)AND (ips.index_id = i.index_id)ORDER BY avg_fragmentation_in_percent DESC
Плюс тяжелые запросы с неоптимальными планами могут подсказать, какие таблицы являются проблемными. Скриптами выше проверьте их состояние.
Но в целом это отдельный разговор. Сегодня об этом речь не идет.
Это еще не конец
Мы прошли долгий путь и каждый шаг дался нам не просто:
- Сначала настроили базовое обслуживание с помощью поставляемых компонентов SQL Server.
- Затем усложнили обслуживание для уменьшения влияния на информационную систему.
- После вынужденно отказались от штатных компонентов и использовали свои скрипты и наработки, поставили ограничения на операции обслуживания, повысили надежность работы и пресекли выход за рамки технологического окна. А также улучшили онлайн обслуживание индексов.
- Далее рассмотрели нюансы при работе в полной модели восстановления базы.
- Разбили обслуживание на регулярное и еженедельное для оптимизации работы.
- Изменили стратегию обслуживания для огромных объектов, внедрив возобновляемое перестроение индексов.
- Рассмотрели особенности обслуживания при использовании AlwaysOn.
- И напоследок обсудили логирование и контроль обслуживания.
Но это не конец пути! Все это лишь показывает, что обслуживание баз данных может адаптироваться под любые требования, было бы желание, деньги и время. Ну и знания, конечно же. Надеюсь, в последнем эта статья поможет и даст старт для изучения вопроса.
Желаю создать свой идеальный план и стратегию обслуживания!
А эта статья должна в этом помочь.